[Webinar] Harnessing the Power of Data Streaming Platforms | Register Now
Pipeline to the Cloud – Streaming On-Premises Data for Cloud Analytics
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
This article shows how you can offload data from on-premises transactional (OLTP) databases to cloud-based datastores, including Snowflake and Amazon S3 with Athena. I’m also going to take the opportunity to explain at each stage the reasons and benefits for doing this.
Let’s start off with the simple question: why? Why would we want to move data from OLTP databases elsewhere? Moving data from transactional databases into platforms dedicated to analytics is a well-established pattern that brings multiple benefits, including:
- Workload isolation: analytics queries won’t impact the source transactional application.
- Workload optimisation: analytics platforms are designed and configured for high-volume, ad hoc querying of data, and often for supporting the kind of specialised functions that analytics requires. OLTP platforms are usually configured for the exact opposite—getting data in quickly.
- Data federation: all the data necessary can be brought together from various systems into one place.
- Cost optimisation: the source databases that underpin applications are often configured for high transactional integrity and resilience of data with very low mean-time-to-recovery (MTTR). Storing large volumes of historical data in such an environment is generally cost prohibitive and unnecessary.
Traditionally, data was offloaded to on-premises solutions such as Oracle Exadata, Teradata, and other dedicated data warehousing environments. In recent years, there has been a huge rise in the availability and use of cloud-based services providing similar capabilities, including Google’s BigQuery, Snowflake, and Amazon Redshift and S3/Athena offerings.
Along with a shift towards cloud-based and often managed analytics platforms, there are also lots of people realising the benefits of moving towards an event streaming architecture and away from one that is batch based.
In the past, getting data from a source system to the target was generally a job for a batch-based ETL (or ELT) tool. Periodically, you’d poll the source system and pull out new data which would then be written to the target system. The data would be manipulated in a way that makes it suitable for querying either beforehand (ETL) or afterwards (ELT). The limitations of this are clear though:
- Latency. Because it’s batch driven, you can’t find out what happened in the source system until the batch has run. The bigger the batch, the longer it takes to process, and thus the even longer delay for your data. Batching data made sense a few decades back when systems were literally taken offline overnight. Nowadays, many systems are always on, so it’s a missed opportunity to process data hours after it’s available.
- Batch extracts of data are usually done as snapshots of current state, which therefore excludes all the intermediate state changes in the data. These state changes (events) describe behaviour and the ability to analyse and understand this behaviour is lost if only the snapshot is captured.
- It’s an inflexible design. If you want to use data from the source system elsewhere, you either pull from it directly (which is inefficient) or you pull it from the target that you loaded it to (which leads to the unnecessary tight coupling of your target into the other system).
This is where Apache Kafka® comes into the picture:
- Kafka provides data that you can stream to your target system in real-time.
- Applications can produce data directly into Kafka, or you can use Kafka Connect to stream data from other systems, including databases and message queues, into Kafka.
- Kafka stores data reliably and durably, so even after it’s been streamed to a target system, it’s still available in Kafka to use with other systems or to resend to the original system if required.
- Since Kafka persists data, the same events generated by a source system that are used to drive analytics in a downstream system can also be used to drive further applications and services, consuming from the same stream of events
- Whilst Kafka can act as a “dumb pipe” and pass data straight through, it can also process data and store the processed data.
- Nowadays we, the engineers, are tasked to build architectures where software is being used by more software. Batch ETL might have been acceptable when it was geared towards a human user that returned to the office in the morning after last night’s batch run. But it is wholly inadequate in an always-on world where more and more business processes are automatically carried out by software—and that’s where Kafka and event streaming come in.
| Learn more: | ||
Sounds interesting? Let’s see what this actually looks like in practice and discuss some of the particular patterns and benefits to note along the way.
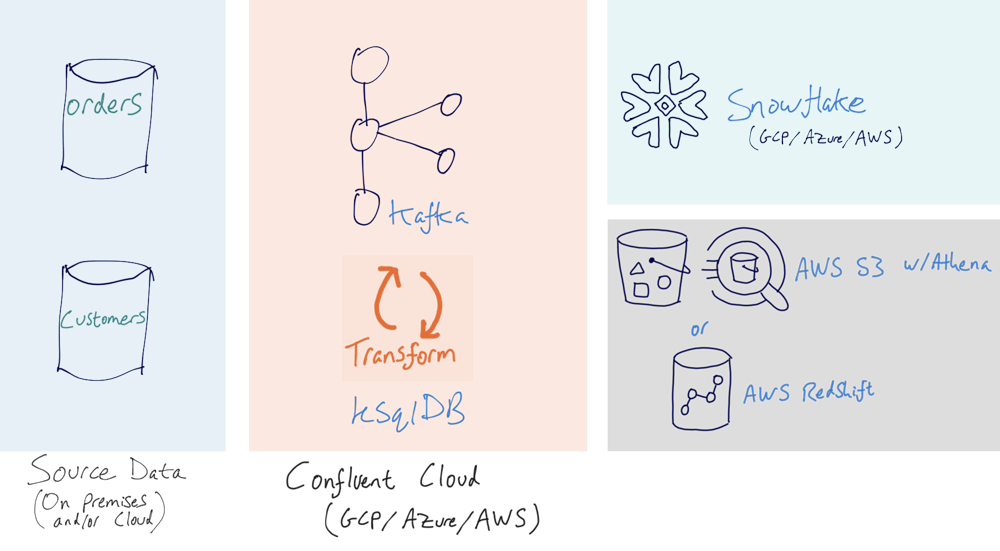
The toolset for database offload to the cloud
- Confluent Platform: An event streaming platform built on Apache Kafka. In my examples, it is provided as a managed service through Confluent Cloud.
- Microsoft SQL Server and MySQL: Proven, reliable relational databases (RDBMS), for which you can also substitute your own preferred RDBMS of choice here if you want. The principles shown are the same. They both provide source data.
- Snowflake: A data warehouse built from the ground up for the cloud, provided as a managed service. The data from the RDBMS source systems will be ingested into Snowflake through Kafka.
- Amazon S3 with Athena: A cloud-hosted datastore with a SQL interface for querying the data. The data from the RDBMS source systems will be ingested into S3 through Confluent Cloud.
There are other cloud analytics platforms—some of them truly cloud native, others being on-premises technology re-badged for the cloud. As with the RDBMS, they are pretty interchangeable with the examples shown here.
All the code for the examples here can be found on GitHub. You can also find a hands-on guide with the nitty-gritty of each step of configuration in this blog post.
I’m going to build the example up over various stages, starting simple and developing it through to become something fairly advanced. Each stage is its own valid entity, and organisations will pick and choose amongst these depending on their requirements and levels of maturity with Kafka and event streaming.
Stage 0: Streaming events from RDBMS to Snowflake with Apache Kafka
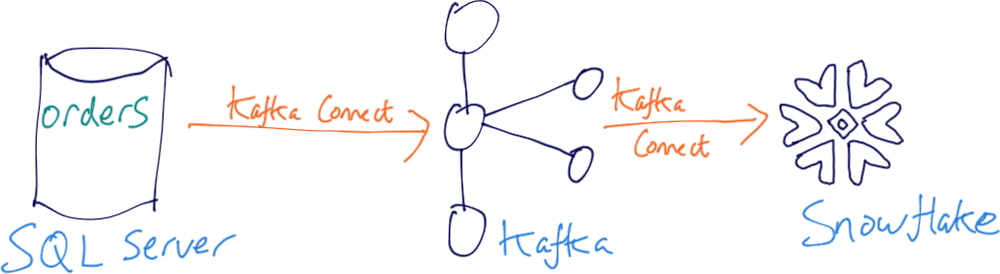
We’ll start with the most simple pipeline. Transactional data is being written to a SQL Server database, and we want to offload it to Snowflake for analysis and reporting.
Data is ingested from the database into Kafka, with an initial snapshot followed by any change made against the tracked table(s)—all streamed into a Kafka topic. From there, the data is streamed right out to Snowflake. All this happens in real-time and is done with Kafka Connect and the appropriate plugins:
| Learn more about Kafka Connect in this talk from Kafka Summit:: | ||
Now this data from the source database:
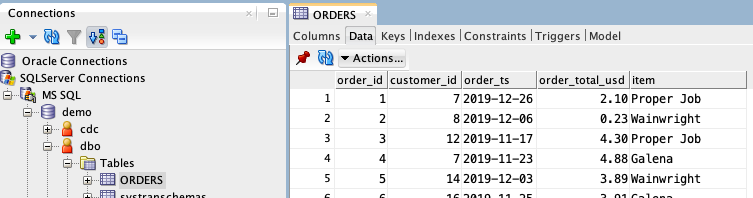
…is available both in Kafka and in Snowflake:
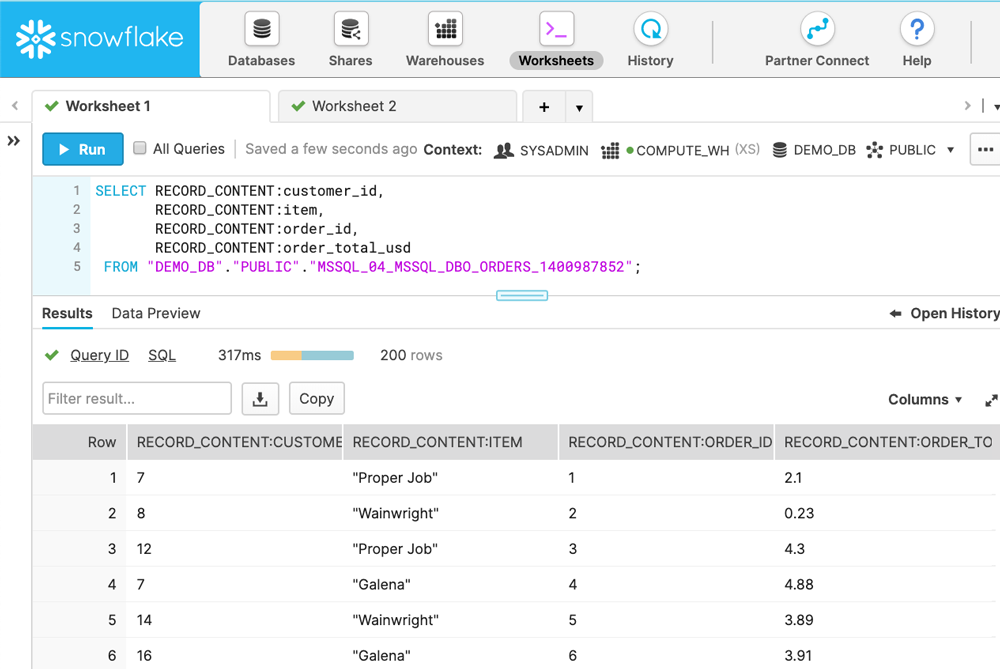
This is a great initial step, but it’s only the beginning. The data in Snowflake is being updated in real time as soon as an INSERT, UPDATE, or DELETE operation changes the source SQL Server database. However, at this point what’s in Snowflake is but a 1:1 copy of the source data. We can do much more, which we will look at next.
Stage 1: Adding reference data
The events that we streamed from SQL Server are what happened; in analytics parlance, they’re the facts. Facts are useful but on their own aren’t the full picture. We might know that a customer with an identifier of 17 bought an item, but we don’t know who that customer is—their email address, where they live, and so on. Having this reference data or dimensional data, however, turns a list of facts into something that’s actually useful to look at and analyse.
It may well be that the source of reference data is not necessarily the same as that of the facts. In our example, it resides on another RDBMS: MySQL. We use the same pattern to ingest it into Kafka and push it to Snowflake:
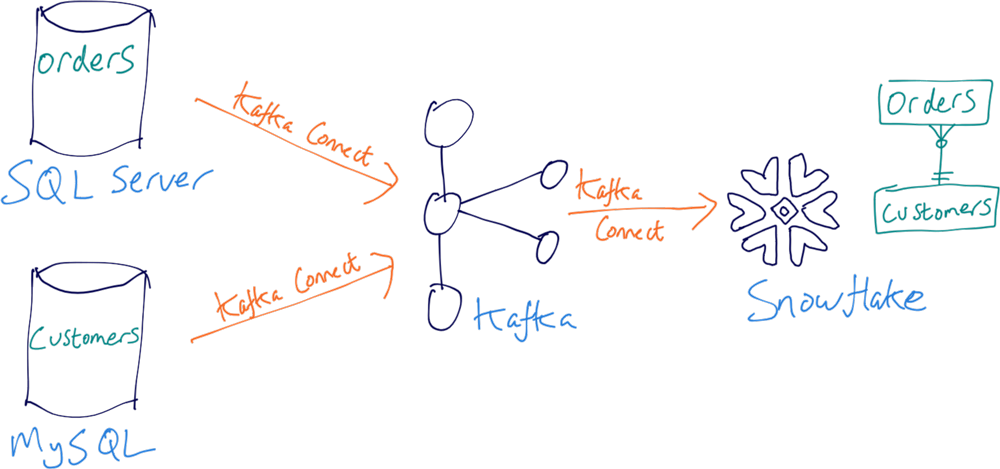
Once both the SQL Server and the MySQL data is in Snowflake, we can join the data in place:
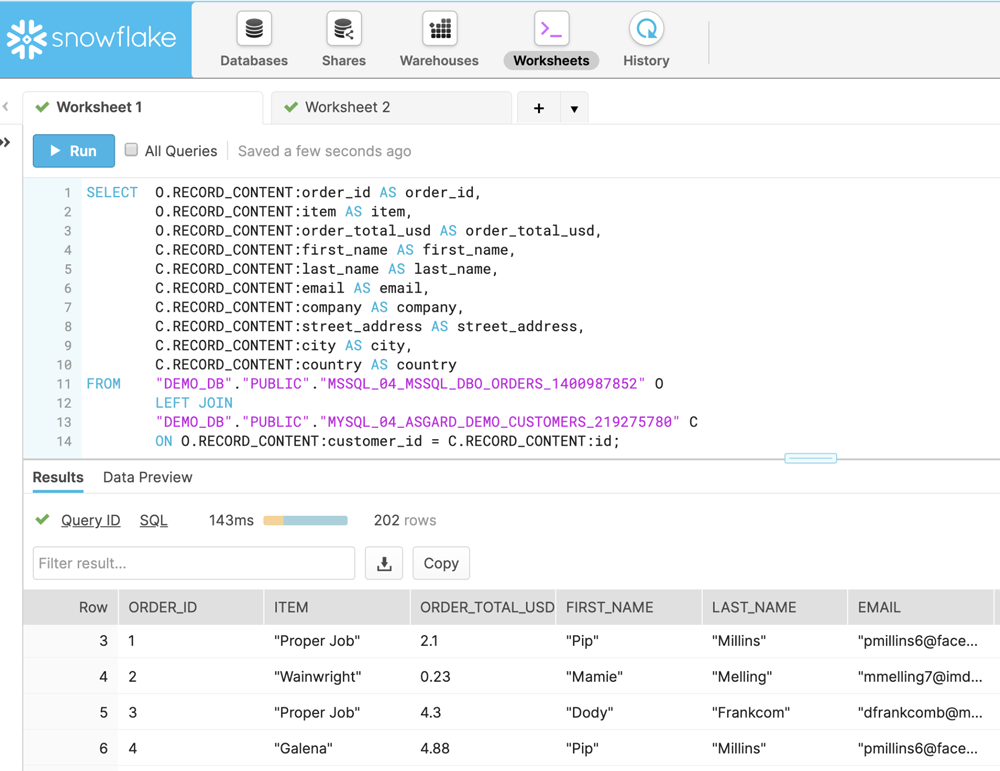
Kafka Connect enables the integration of data from the RDBMS but also from numerous other sources too. The above pattern can be used to great effect for federating data from many different places, including message queues, flat files, as well as directly from applications.
Stage 2: Stream processing
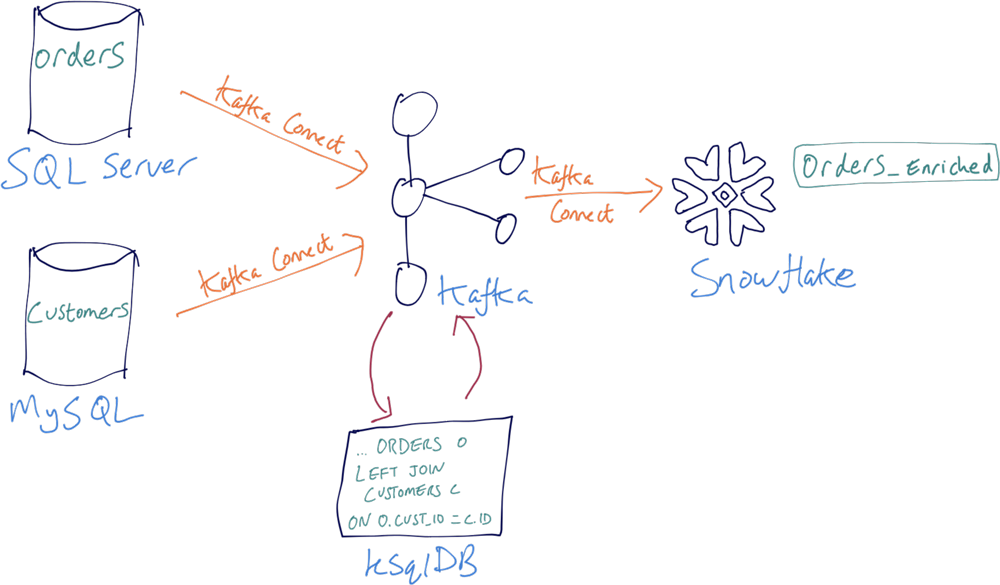
Kafka is not just a “dumb pipeline”; it is an event streaming platform that enables us to store data for reuse, and it also provides stream processing capabilities. You can use the Kafka Streams API, which is a Java and Scala library that is part of Apache Kafka. Or if you prefer something higher level, there’s the event streaming database ksqlDB.
Using ksqlDB, you can express and build stream processing applications that will look rather familiar to anyone who knows SQL 🙂
CREATE STREAM ORDERS_ENRICHED AS SELECT O.order_id AS order_id, O.item AS item, O.order_total_usd AS order_total_usd, C.first_name || ' ' || C.last_name AS full_name, C.email AS email, C.company AS company, C.street_address AS street_address, C.city AS city, C.country AS country FROM ORDERS O LEFT JOIN CUSTOMERS C ON O.customer_id = C.id;
The result of this query is a Kafka topic populated with denormalised data, joining facts (orders) with the dimension (customer). Denormalising data in advance of querying is a well-established pattern for performance. This is because most times querying a single table of data will perform better than querying across multiple at runtime.
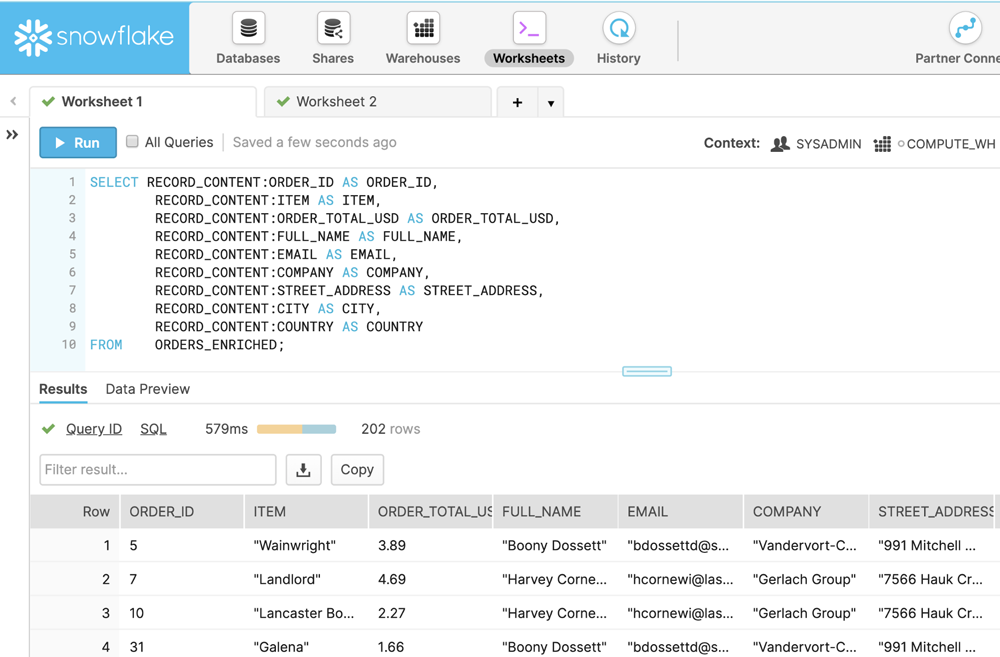
The stream processing results are written back to a Kafka topic, and since it’s just a Kafka topic, it can then be streamed to the target as before:
This gives us a single table in Snowflake to query, without needing any joins. The benefit of doing this prior to loading the data into Snowflake is that the query in Snowflake is simpler to write and may well be faster to execute. It also means, as we will see later, that we can reuse this denormalised data elsewhere.
Denormalisation is just one example of where stream processing can form part of the ETL/ELT process. Other things that you can do with stream processing include:
- Data wrangling, including schema manipulation, conditional replacement of values, bucketing data, applying labels, and data routing
- Stateful aggregation, in which you can calculate an aggregate (SUM, COUNT, etc.) on data that is split into “windows” (tumbling, hopping, or session)
- Join data between Kafka topics modelled as streams or tables (supported joins are stream-stream, stream-table, and table-table)
Regardless of what the processing you’re doing is, this has always been previously done as a batch either on the target system (ELT) or before loading it (ETL). Now, we’re doing this traditional transform processing as a stream on the events as they’re occurring instead of as a slow batch in the middle of the night. The transformed data is streamed back into a Kafka topic for use downstream, and there are several benefits to this:
- Data is available for use as soon as the event has happened. There is no artificially created latency like for batch processing.
- Processing data as it occurs is more likely to avoid the bottlenecks that result from processing large batches of data accumulated over time.
- Writing the enriched data back into Kafka makes it available for other systems to use without having to re-poll from the source or re-process the data themselves.
In particular, I’d like to explore the last point further since it’s such a powerful feature.
Stage 3: Transform once; use many
One could easily argue that in the example above, the join on the data could be done on the target system (in this case, Snowflake). It could be done either at query runtime if performance is acceptable or be pre-computed as part of the ETL/ELT process, with the results written to a new table in Snowflake.
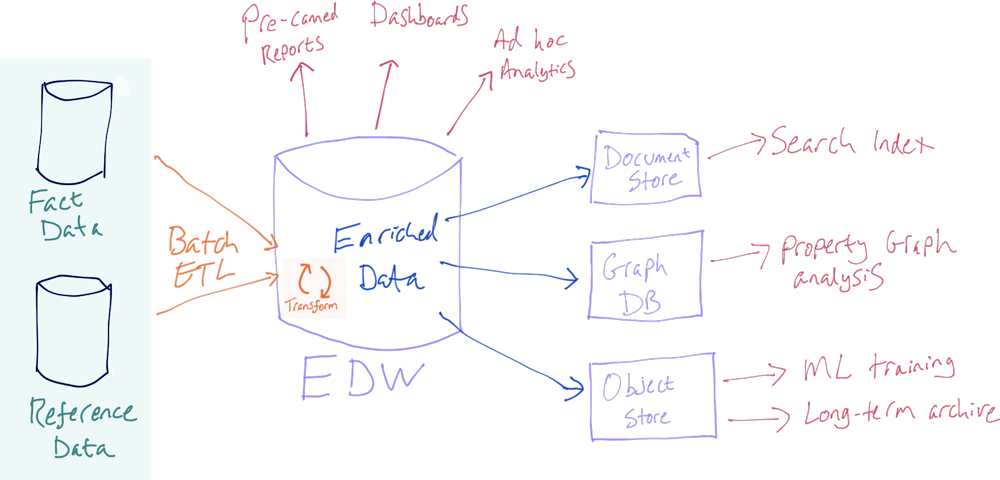
But, what about other users of this data? Let’s take a step back and consider this from a more abstract point of view. With the same data being used by multiple teams and systems in an organisation there are several approaches to take.
Previously, we would have done this, in which any other user of the data is dependent on the data warehouse (adding load to it and introducing it as an unnecessary dependency):
Or, we would have done this, in which other users of the data each pull it directly from the source (adding load to a transactional system) and each perform the transformations on it (duplicating code):
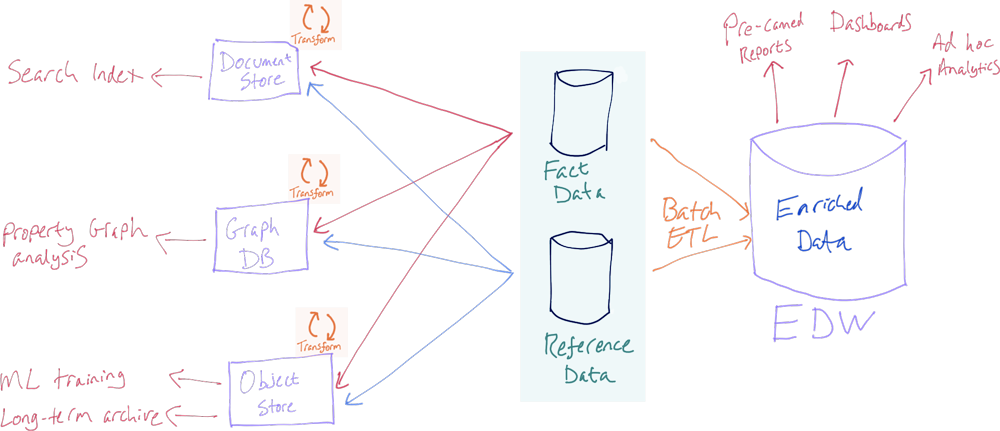
The world has thankfully moved on from a single team being the gatekeeper of a single central data warehouse from which all queries must be served. Striving for data quality and consistency in definitions is indeed important and completely relevant now more than ever, but what has changed is that numerous teams throughout an organisation will want the same data yet often on a different platform. And that is OK. It’s not just OK, it actually makes a huge amount of sense. Trying to serve the same data from a single platform for multiple purposes is often not a great idea. Why would we build a search index on data in an RDBMS, do property graph analysis on data held in a document store, or build complex aggregate queries on data in a NoSQL store?
Each technology has its strengths and weaknesses, and by using the most appropriate tool for the job we can deliver business benefits from the data more quickly and reliably. In the past, it was frowned upon to have secondary copies of data elsewhere for both valid reasons (such as data security, data consistency, and overly complex architectures) and invalid reasons (such as empire building, an unwillingness to share, and organisational politics). By using Kafka, we can address almost all these issues and provide a flexible foundation on which to make data available across applications and teams, whilst still enforcing security and governance.
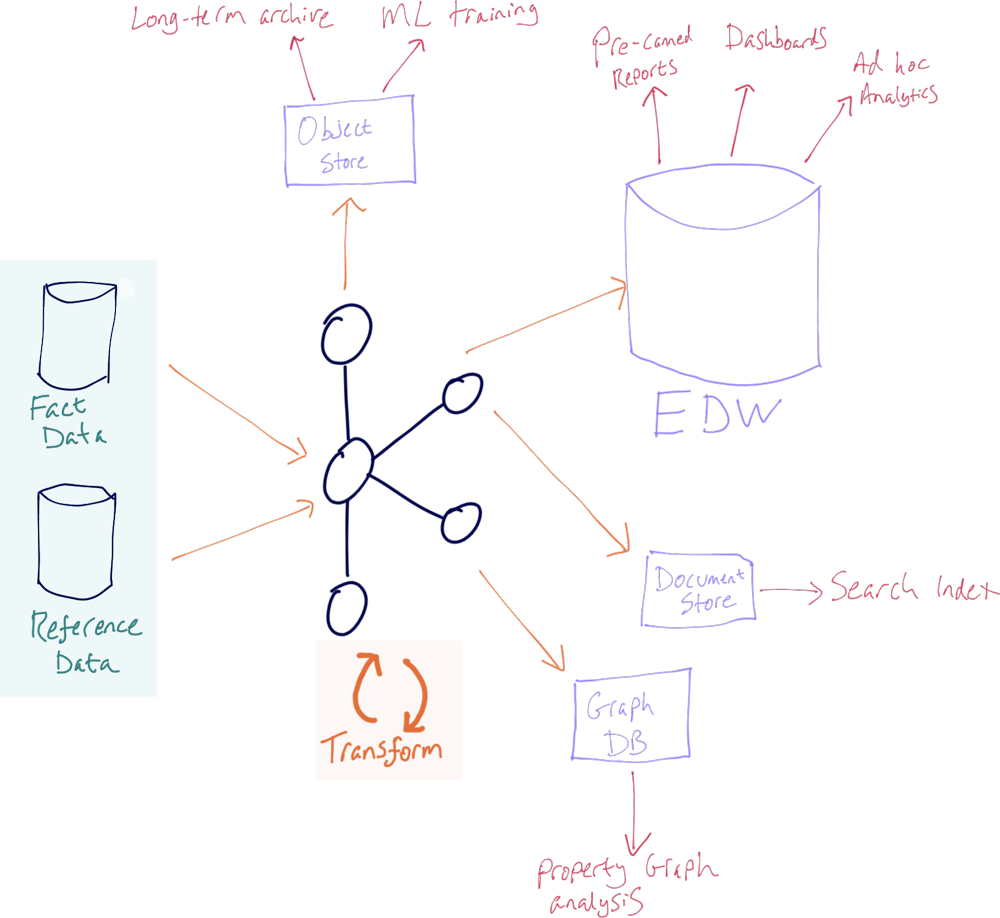
Advantages to this approach include:
- Each target datastore can be taken offline, upgraded, or replaced without impacting any of the others. This is a tremendous benefit particularly for larger enterprises, where different teams with often conflicting objectives and timelines need to coordinate their work. It enables organizations to make improvements and changes to their infrastructures much safer and faster.
- Standard transformations (e.g., denormalisation) can be applied at the source instead of needing to be done on each system.
- Data cleansing can be done once and maintained in a single codebase as opposed to multiple times across consuming systems, which would inevitably lead to the divergence of code and associated data quality issues.
- The raw data is still available if target datastores and applications want it.
- Applications can be driven from the same enriched data that drives analytics.
- Because Kafka is a highly scalable and resilient distributed system, it is much less of a single point of failure (or performance bottleneck) than something like an RDBMS can often be.
| ℹ️ In all of this, the Kafka brokers themselves are just infrastructure; the code that does the processing and enriching is not owned centrally but instead by whichever party decides to own that processing. Conversely, the code could be owned centrally if so desired from an organisational point of view. This is one of the reasons why Kafka used properly is not reinventing the enterprise service buses (ESBs) of the past and their associated problems. For more discussion around this, see Kai Waehner’s excellent articles on the matter: |
||
Let’s relate this back to what we’ve been building so far. Because we already have the data in Kafka, both raw and transformed, we can simply add another connector to stream the data to Redshift or to S3 for analysis in Athena—or even both if desired.
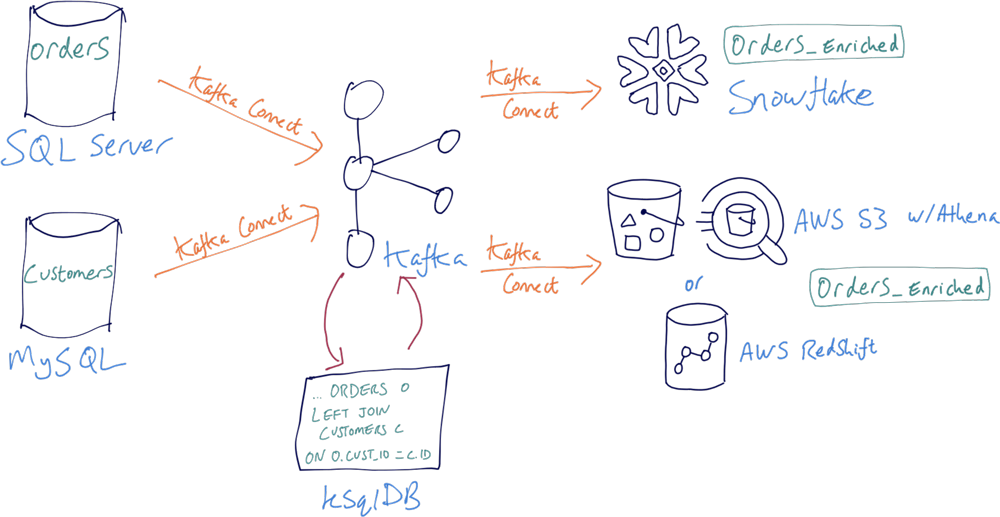
Now consider how this architecture favourably positions us for future changes:
- The source database is taken offline/needs to scale/is replaced—no problem. The source topic still gets the data whenever it’s available, even if it’s a different platform. The target datastore(s) are completely unaware of where the data originates from; they just pull it from the Kafka topic.
- The enriched data transformation is maintained once, and in one place. That one place is Kafka—a highly scalable, fault-tolerant, event-based platform.
- The target datastore(s) are independent of each other. One going offline doesn’t affect the other. They can be replaced or added to without making an impact elsewhere.
- It provides a very powerful and clean migration path between an existing technology and a new one providing the same data. For example, migrating from one RDBMS to another, upgrading versions of the same RDBMS, or moving from on-premises to cloud. Consuming applications are gradually cut over to the new technology, until all are now using the new system. Throughout all of this both systems are receiving the same data, and the existing system continues to be available until it is no longer required and can simply be switched off with no “big bang” crossover.
Let’s take a quick look at what streaming data to S3 from Kafka looks like in practice. Setting up an S3 sink is particularly easy because it’s offered as a managed connector in Confluent Cloud, and with a couple of clicks you’re all set:
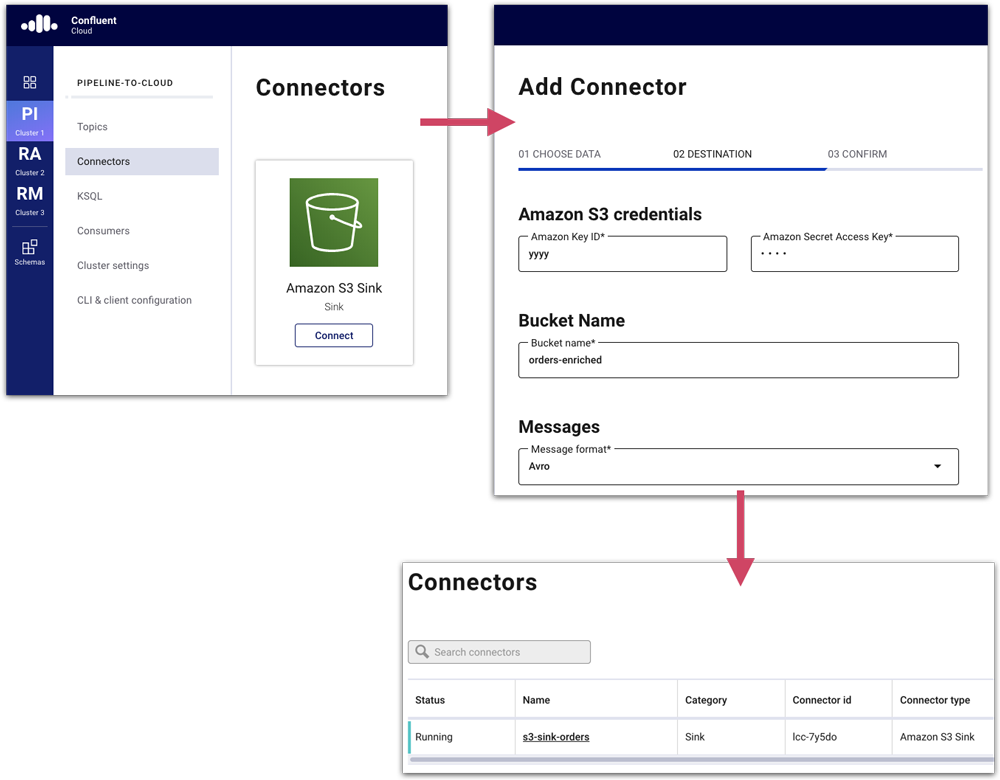
Now we have data flowing from the source system into Kafka, being enriched and transformed by ksqlDB and written back to Kafka. From here, it’s streamed to both Snowflake and Amazon S3, but this is just an example. You can stream data from Kafka to pretty much any target, including a JDBC-supporting datastore, Google’s BigQuery, Azure Blob storage…the list goes on.
With Confluent Cloud and managed connectors, the deployment becomes even easier too:
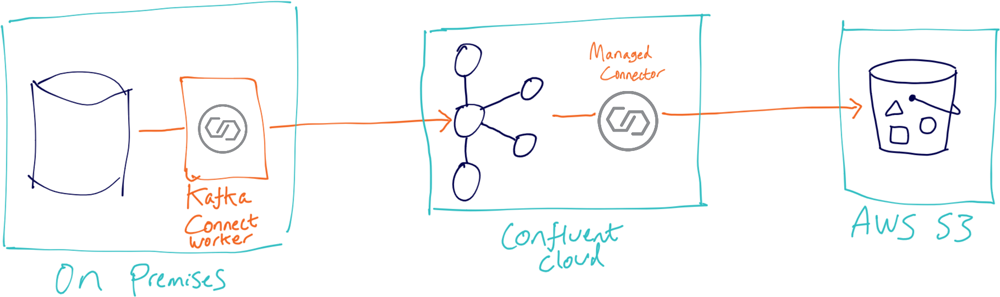
Where does this run?
I’ve talked a lot about the logical architecture here and the considerations and benefits of building it out in the way that I have shown. To wrap up, let’s discuss where the different pieces of the stack actually reside so you can start building from it today.
Source database
This is assumed to be already provisioned either on premises or in the cloud.
Snowflake
Snowflake is a managed service available on Google Cloud Platform (GCP), Microsoft Azure, and Amazon Web Services (AWS).
Kafka
The Kafka cluster can be provisioned as a managed service like Confluent Cloud on GCP, Azure, or AWS, or run self-managed on premises or in the cloud.
Kafka Connect
Confluent Cloud includes some managed connectors, including one for S3. Other connectors have to be self-managed. When it comes to deploying these, you can do it in different ways. For example:
- Entirely on premises
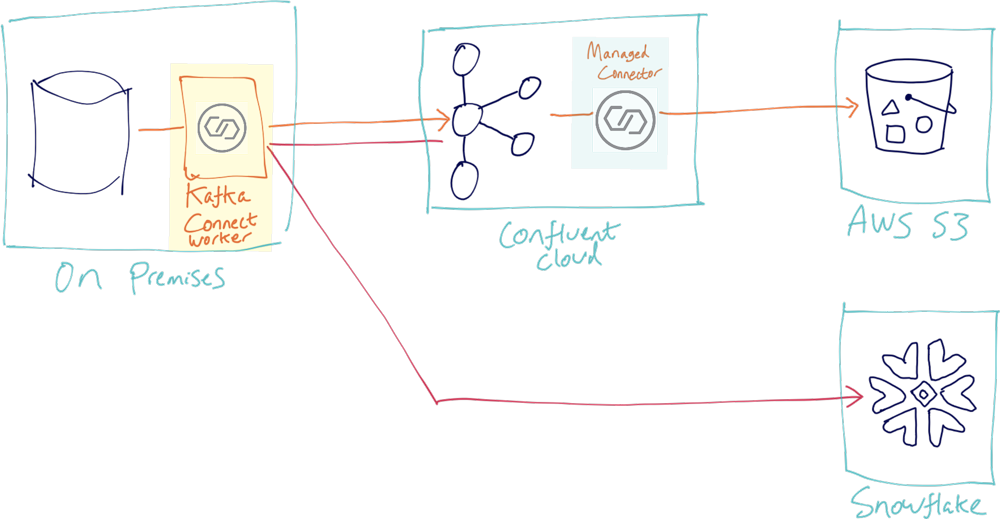
If you run it on premises, you have potential networking inefficiencies in fetching data from Kafka in the cloud locally to push it back up to Snowflake (in the cloud).
- Using IaaS (such as Amazon EC2) to run the Kafka Connect worker in the cloud
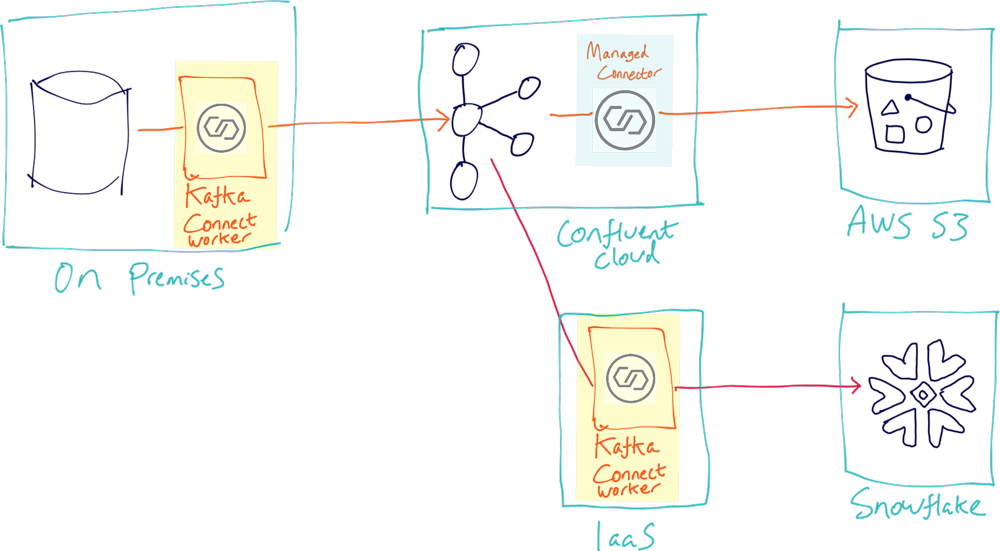
Conclusion
What I’ve shown above is just one way of building out modern data pipelines with event streaming, bringing data from a source that may well be on premises up into the cloud, and doing all this in near real time. Confluent Cloud provides a managed service for event streaming with Kafka, Confluent Schema Registry, ksqlDB, and Kafka Connect. To learn more, you can check out Confluent Cloud, a fully managed event streaming service based on Apache Kafka, and try it for free with up to $50 USD off your bill each calendar month. You can try out all the code shown in this article on GitHub.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...