Introducing Connector Private Networking: Join The Upcoming Webinar!
How to Use Single Message Transforms in Kafka Connect
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Kafka Connect is the part of Apache Kafka® that provides reliable, scalable, distributed streaming integration between Apache Kafka and other systems. Kafka Connect has connectors for many, many systems, and it is a configuration-driven tool with no coding required. There is also an API for building custom connectors that’s powerful and easy to build with. You can learn more about Kafka Connect in the talk From Zero to Hero with Kafka Connect and read about it in action on the blog.
The Kafka Connect API also provides a simple interface for manipulating records as they flow through both the source and sink side of your data pipeline. This API is known as Single Message Transforms (SMTs), and as the name suggests, it operates on every single message in your data pipeline as it passes through the Kafka Connect connector.
Connectors are classified as either sources or sinks—they either pull data from a system upstream of Kafka or push data downstream from Kafka. These connectors can be configured to take advantage of transforms on either side. Source connectors pass records through the transformation before writing to the Kafka topic, and sink connectors pass records through the transformation before writing to the sink.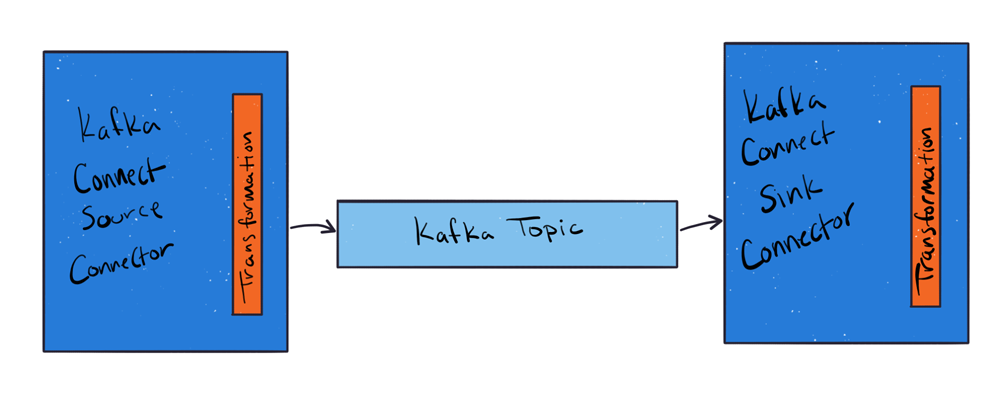
Some common uses for transforms are:
- Renaming fields
- Masking values
- Routing records to topics based on a value
- Converting or inserting timestamps into the record
- Manipulating keys, like setting a key from a field’s value
Kafka ships with a number of prebuilt transformations, but building custom transformations is quite easy as you’ll see in this blog post.
Configuring Kafka Connect Single Message Transforms
Transforms are given a name, and that name is used to specify any further properties that the transformation requires. For example, here’s a snippet of the example configuration for the JDBC source to leverage the RegexRouter transformation. This transform appends a fixed string to the end of the topic being written to:
{
“name”: "jdbcSource",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
# —- other JDBC config properties —-
"transforms": "routeRecords",
"transforms.routeRecords.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.routeRecords.regex": "(.*)",
"transforms.routeRecords.replacement": "$1-test"
[…] }
}
The transform has been identified with the name routeRecords, and that name is used in the subsequent keys for passing properties. Notice the above example shows two configuration properties for RegexRouter: the regular expression regex, and the replacement referencing the match group. This setup will take the table name from the JDBC source and renames it with a -test suffix. Transforms may have different configuration properties depending on what the transform does. You can check the documentation for more details.
Performing multiple transformations
Sometimes more than one transformation is necessary. Kafka Connect supports defining multiple transformations that are chained together in the configuration. These messages flow through the transformations in the same order in which they are defined in the transforms property.
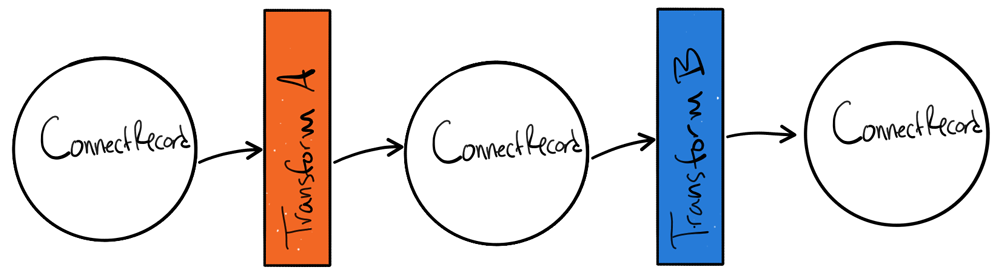
Chained transformation example
Robin Moffatt wrote a blog post featuring a chained set of transformations that converts a value to a key using the ValueToKey transform, along with the ExtractField transform to use just the ID integer as the key:
“transforms”:”createKey,extractInt”, “transforms.createKey.type”:”org.apache.kafka.connect.transforms.ValueToKey”, “transforms.createKey.fields”:”c1”, “transforms.extractInt.type”:”org.apache.kafka.connect.transforms.ExtractField$Key”, “transforms.extractInt.field”:”c1”
Notice with the $Key notation above, we’re specifying that this transformation should act on the Key of the record. To act on the Value of the record, you’d specify $Value here. As a result, a ConnectRecord that looks like this:
key value
------------------------------
null {"c1":{"int":100},"c2":{"string":"bar"}}
…ends up looking like this:
key value
------------------------------
100 {"c1":{"int":100},"c2":{"string":"bar"}}
What should (and shouldn’t) you use transforms for?
Transforms are a powerful concept, but they should only be used for simple, limited mutations of the data. Don’t call out to external APIs or store state, and don’t attempt any heavy processing in the transform. Heavier transforms and data integrations should be handled in the stream processing layer between connectors using a stream processing solution such as Kafka Streams or KSQL. Transforms cannot split one message into many, nor can they join other streams for enrichment or do any kinds of aggregations. Such activities should be left to stream processors.
If you’re curious about learning more, I highly recommend checking out this related Kafka Summit talk: Single Message Transformations Are Not the Transformations You’re Looking For.
Deep dive on Single Message Transforms
Let’s take a deeper look into how connectors work with data. Unless you want to write your own Single Message Transform, or are just interested in what happens under the covers when you use a transform, feel free to skip this section and join us again for the conclusion at the end of this article.
Transformations are compiled as JARs and are made available to Kafka Connect via the plugin.path specified in the Connect worker’s properties file. Once installed, the transforms can be configured in the connector properties.
Once configured and deployed, a source connector receives records from an upstream system, converts it to a ConnectRecord, and then passes that record through the apply() function of the transformation(s) that have been configured, expecting a record back. The same process happens for a sink connector, but in reverse. After reading and deserializing each message from the source Kafka topic, the apply() function of the transformation(s) is called, and the resulting record is sent to the target system.
How do you write a Single Message Transform?
To build a simple transformation that inserts a UUID into each record, let’s walk through the steps below. The code is also available on GitHub.
Apply functions are the core of transformations. This transform supports data with and without a schema, so there’s one transform for each. The main apply() method routes the data appropriately:
@Override
public R apply(R record) {
if (operatingSchema(record) == null) {
return applySchemaless(record);
} else {
return applyWithSchema(record);
}
}
private R applySchemaless(R record) {
final Map<String, Object> value = requireMap(operatingValue(record), PURPOSE);
final Map<String, Object> updatedValue = new HashMap<>(value);
updatedValue.put(fieldName, getRandomUuid());
return newRecord(record, null, updatedValue);
}
private R applyWithSchema(R record) {
final Struct value = requireStruct(operatingValue(record), PURPOSE);
Schema updatedSchema = schemaUpdateCache.get(value.schema());
if(updatedSchema == null) {
updatedSchema = makeUpdatedSchema(value.schema());
schemaUpdateCache.put(value.schema(), updatedSchema);
}
final Struct updatedValue = new Struct(updatedSchema);
for (Field field : value.schema().fields()) {
updatedValue.put(field.name(), value.get(field));
}
updatedValue.put(fieldName, getRandomUuid());
return newRecord(record, updatedSchema, updatedValue);
}
This transform can be applied to either record keys or values, so we need to implement Key and Value subclasses that extend the main InsertUuid class and implement the newRecord function that the apply functions use:
public static class Key<R extends ConnectRecord<R>> extends InsertUuid<R> {
@Override
protected Schema operatingSchema(R record) {
return record.keySchema();
}
@Override
protected Object operatingValue(R record) {
return record.key();
}
@Override
protected R newRecord(R record, Schema updatedSchema, Object updatedValue) {
return record.newRecord(record.topic(), record.kafkaPartition(), updatedSchema, updatedValue, record.valueSchema(), record.value(), record.timestamp());
}
}
public static class Value<R extends ConnectRecord<R>> extends InsertUuid<R> {
@Override
protected Schema operatingSchema(R record) {
return record.valueSchema();
}
@Override
protected Object operatingValue(R record) {
return record.value();
}
@Override
protected R newRecord(R record, Schema updatedSchema, Object updatedValue) {
return record.newRecord(record.topic(), record.kafkaPartition(), record.keySchema(), record.key(), updatedSchema, updatedValue, record.timestamp());
}
}
This transform only changes the schema and value, but notice that we can manipulate all parts of the ConnectRecord: the Key, the Value, the Key and Value schemas, destination topic, destination partition, and timestamp.
This transform has optional parameters that are set at runtime and accessed via the overridden configure() function in the transform class:
@Override
public void configure(Map<String, ?> props) {
final SimpleConfig config = new SimpleConfig(CONFIG_DEF, props);
fieldName = config.getString(ConfigName.UUID_FIELD_NAME);
schemaUpdateCache = new SynchronizedCache<>(new LRUCache<Schema, Schema>(16));
}
As you can see, the transformation interface is straightforward—it implements an apply() function that receives a ConnectRecord—and returns a ConnectRecord. Optionally, it can provide parameters via the configure() function.
Next, compile this JAR and put it into a path specified in plugin.path on the Connect worker. Keep in mind that you’ll need any dependencies the transform depends on to be packaged with it, either in the path or compiled as a fat JAR. Invoke it in your connector configuration as follows (notice the $Value inner class convention to denote that this transform should act on the Value of the record):
transforms=insertuuid transforms.insertuuid.type=com.github.cjmatta.kafka.connect.smt.InsertUuid$Value transforms.insertuuid.uuid.field.name="uuid"
Conclusion
Single Message Transforms are a powerful way to extend Kafka Connect for the purpose of data integration. You can reuse prebuilt transformations or create one easily as shown above.
Interested in more?
If you’d like to know more, you can download the Confluent Platform to get started with Single Message Transforms and the leading distribution of Apache Kafka.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Kafka-docker-composer: A Simple Tool to Create a docker-compose.yml File for Failover Testing
The Kafka-Docker-composer is a simple tool to create a docker-compose.yml file for failover testing, to understand cluster settings like Kraft, and for the development of applications and connectors.


How to Process GitHub Data with Kafka Streams
Learn how to track events in a large codebase, GitHub in this example, using Apache Kafka and Kafka Streams.