[Webinar] Harnessing the Power of Data Streaming Platforms | Register Now
Kafka Connect Sink for PostgreSQL from JustOne Database
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Introducing a Kafka Sink Connector for PostgreSQL from JustOne Database, Inc.
JustOne Database is great at providing agile analytics against streaming data and Confluent is an ideal complementary platform for delivering those messages, so we are very pleased to announce the release of our sink connector that can stream messages at Apache Kafka speed into a table in a PostgreSQL compatible database. This connector works with any database compatible with PostgreSQL 9.3 (and above) which supports the PostgreSQL COPY interface and the PL/pgSQL language extension – this includes the free downloadable version of JustOneDB. The Use Case and Performance sections below provide an overview of how Kafka and JustOneDB can support the acquisition of data at network speed, while leveraging the same database instance to support agile analytics. The remaining sections of this post take a look at how the connector works, how to setup a test environment, and how you can use it. The connector is open source and you can find the connector source and executables here: https://github.com/justonedb/kafka-sink-pg-json.
Use Case
Although the connector can be used with any PostgreSQL compatible database, it was specifically developed for use in an architecture using Kafka and JustOneDB to provide a relational data lake where all of the messages from across the enterprise are collected into one place – for data exploration and discovery activities using standard business intelligence and presentation clients.
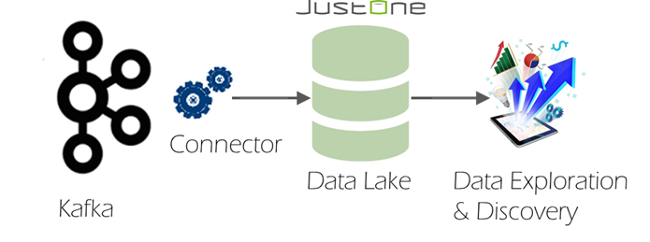
This architecture works simply because of the performance and scalability of both solutions. We know that Kafka can stream data like a firehose; and JustOneDB is able to drink from that firehose while providing interactive agile query access to that data even at data volumes extending into hundreds of terabytes. The beauty of a relational data lake is that the relational paradigm provides data transparency to the users exploring it; while JustOneDB provides the query agility and interactive response times demanded by data analysis and exploration by clients and users.
When testing the connector with JustOneDB we have seen consumption rates matching those of an un-indexed PostgreSQL table – but the key difference is that JustOneDB does not need any indexes added or any data transformations to yield fast interactive response times for analytical queries and for fast drill downs into the granular detail behind those analytical results. This architecture allows you to potentially keep everything and query anything – without the cost and complexity of something like Hadoop or a large data appliance.
There is a free downloadable version of JustOneDB at https://www.justonedb.com if you want to try this for yourself and see how easy it is to create a relational data lake.
Performance
So how quickly can the connector stream messages from Kafka into a database? We ran a test on a single small server with 32GB of memory and 6 CPU cores hosting both Kafka and a PostgreSQL 9.3 database. We pre-loaded Kafka with 2 million messages with an average length of 128 bytes and then ran the sink connector subsequently in standalone mode to measure how long it took to consume those messages; and with statement logging in the database we traced how long the connector operations took.
With an unindexed table, a single task was able to stream over 200,000 messages/second using synchronized delivery. We also measured 300,000 messages/second when the number of partitions and tasks was increased to two.
Clearly, an unindexed table becomes sizeable very quickly at this rate – after one hour of consuming messages at 300,000 messages/second the table will already contain over a billion rows. At that size a PostgreSQL table will need to add some indexing to make it practical for queries – and indexes usually mean much slower inserts at these kinds of volumes. But the point here is that Kafka and the connector can stream the data as fast as you need them to. More importantly if you are using the JustOneDB database which is Postgres 9.3 compatible, you will be able to ingest data at the aforementioned rates but will also see query performance as if the data was fully indexed without the burden of indexing.
Converting from Messages to Rows
One of the central design considerations for a database sink connector is deciding how to convert from the message format delivered by Kafka into a relational row expected by the database. Kafka naturally transports data in Avro format and delivers messages in JSON format – so this connector is able to receive messages in an arbitrary JSON format and parse/convert them into relational rows.
To do this the connector uses the following properties:
- columns – a list of the columns to be populated in each row
- json.parse – a list of the parse paths for extracting elements from each JSON message into respective column values
Each parse path describes the parse route through the message to an element to be extracted from the message. A parse path represents an element hierarchy and is expressed as a string of element identifiers, separated by a delimiting character (typically /).
- A child element within an object is specified using @key where key is the key of the child element.
- A child element within an array is specified using #index where index is the index of the child element (starting at 0).
A path must start with the delimiter used to separate element identifiers and this first character is completely arbitrary so that it can be chosen to avoid any conflict with key names.
Below are some examples for paths in the following message:
{"identity":71293145,
"location":{"latitude":51.5009449,
"longitude":-2.4773414},
"acceleration":[0.01,0.0,0.0]}
- /@identity – the path to element 71293145.
- /@location/@longitude – the path to element -2.4773414.
- /@acceleration/#0 – the path to element 0.01
- /@location – the path to element {“latitude”:51.5009449, “longitude”:-2.4773414}
The extracted element may be any JSON type (null, boolean, number, string, array, object) and the extracted element is placed into a column in the target table. The data type of a column receiving an element must be compatible with the element value passed to it. For example, the data type of the column receiving the longitude element could be a NUMERIC, REAL or VARCHAR. When a non-scalar element (object or array) is passed into a column, the target column should be a TEXT, JSON or VARCHAR data type. For numeric and date/time columns, the sink connector follows all of the standard PostgreSQL parsing conventions for recognising number types and date/time formats.
The parse paths in the db.json.parse property correspond by list position with the column names in the db.columns property, so that the first column in the list is populated using the first parse path etc.
For example, to insert messages in the above message format into a table with an id, latitude, longitude and acceleration columns, the db.columns and db.json.parse configuration properties would be:
db.columns = id,latitude,longitude,acceleration
db.json.parse = /@identity,/@location/@latitude,/@location/@longitude,/@acceleration
Where a path does not exist in the JSON message, a null value is placed in the column value. So /@foo/@bar would return a null value from the example message above. For this reason it is advisable to use the Kafka Schema Registry to enforce the schema on messages delivered to Kafka.
Inserting Rows into the Table
This connector is for use with PostgreSQL compatible databases and it takes advantage of the PostgreSQL COPY interface which can be significantly faster than SQL inserts over JDBC. Indeed, as you will see, we have been able to stream hundreds of thousands of messages per second from Kafka into an un-indexed PostgreSQL table using this connector.
The following connector properties are used for establishing a connection to the target database:
- db.host – name or address of the host server
- db.database – name of the database
- db.username – name of the user to connect with
- db.password – password to authenticate the user by
The host and password properties are optional and default to localhost:5432 and none respectively.
The following properties are used to define the target sink table:
- db.schema – name of the schema of the target table (eg. public)
- db.table – name of the table to receive the rows
Delivery Semantics
This connector provides three delivery modes:
- Fastest – a message will be delivered at most once (but may be lost).
- Guaranteed – a message will be delivered at least once (but may be duplicated)
- Synchronized – each message will be delivered exactly once.
The delivery mode is set using the db.delivery property.
With the fastest mode, the connector only flushes its internal buffer when the buffer fills – independently of when Kafka flushes its offsets. Therefore it is possible that Kafka can deliver a message that never gets flushed to the database.
When using the guaranteed mode, the connector flushes its internal buffer when Kafka flushes its offsets, but it does not store any Kafka state in the database during the flush. Therefore it is possible that Kafka can re-deliver an already received message after a connector restart.
For synchronized delivery, the connector flushes its internal buffer at the point that Kafka flushes its offsets and also stores the Kafka offset state in the database during the flush operation. This Kafka state is used to reset the consumption context in Kafka on connector restart to avoid consuming duplicate messages.
During a flush in synchronized mode, the rows are inserted into the target table and the Kafka state is updated in the same transaction to guarantee one-time delivery. A slight wrinkle here is that the COPY interface operates with its own transactions – therefore the rows are inserted into a temporary table via the COPY operation and are only moved to the target table during the Kafka flush request. This also circumvents any problems caused by the internal connector buffer being flushed independently of a Kafka flush event – which can happen when the buffer becomes full. The connector actually uses a set of database functions to perform start synchronization and flushing transactions.
Our experience has shown that there is minimal performance overhead in using a synchronized delivery mode and therefore this is the default delivery semantic.
Buffer Size
We have mentioned an internal connector buffer and you can set the size of this buffer using the db.buffer.size property.
For best performance this should be large enough to be able to accommodate all of the rows delivered by Kafka between flush operations. If using synchronized or guaranteed delivery, it does not matter if the buffer size specified is too large – as the buffer will not grow any larger than that required to store rows between flush operations. However, for the fastest delivery mode, the buffer will grow to the configured size, because, in this mode the connector only flushes the buffer when it becomes full.
The default size of 8MB is generally a reasonable buffer size to use – but if you increase it beyond this you may need to increase your java heap size using something like the following before starting the Kafka broker.
$ export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
Walkthrough
Now let’s step through how you install and use the connector with the Confluent 2.0 platform and PostgreSQL.
- You will need Confluent 2.0 installed and running (Zookeeper, Kafka broker and Schema Registry). You will also need PostgreSQL 9.3 (or later) installed and running.
- Create a directory for the connector and make it your current directory.
- Download the justone-kafka-sink-pg-json-1.0.zip file from the latest release at https://github.com/justonedb/kafka-sink-pg-json/releases and unzip it into your directory.
- Install the connector package in the database you will be connecting to by using the following command within a psql session connected to your database:
# \i install-justone-kafka-sink-pg-1.0.sql
- Edit the justone-kafka-sink-pg-json-connector.properties file and set the following:
- topics – the topic to consume from
- host – the server address/name of the database host if not the local host
- database – the database to connect to
- username – the username to connect to the database with
- password – the password to use for user authentication, if required
- schema – the schema of the sink table, eg. public
- table – the name of the sink table to receive the rows
- columns – comma separated list of columns to receive values
- json.parse – comma separated list of parse paths to retrieve json elements by
- Add the jar files to your class path using
$ export CLASSPATH=$PWD/*
- Run the connector in standalone, using the command:
$ $CONFLUENT_HOME/bin/connect-standalone justone-kafka-sink-pg-json-standalone.properties justone-kafka-sink-pg-json-connector.properties
- Now you can push messages into Kafka and through to your target table.
This blog post was written by guest blogger Duncan Pauly from JustOne. JustOne is a member of the Confluent partner program.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



How to Process GitHub Data with Kafka Streams
Learn how to track events in a large codebase, GitHub in this example, using Apache Kafka and Kafka Streams.



Introducing Apache Kafka 3.7
Apache Kafka 3.7 introduces updates to the Consumer rebalance protocol, an official Apache Kafka Docker image, JBOD support in Kraft-based clusters, and more!