Introducing Connector Private Networking: Join The Upcoming Webinar!
Transferring Avro Schemas Across Schema Registries with Kafka Connect
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Although starting out with one Confluent Schema Registry deployment per development environment is straightforward, over time, a company may scale and begin migrating data to a cloud environment (such as through the now generally available Confluent Cloud Schema Registry). In other cases, large organizations may share their data with subsidiaries. Such cloud offerings and separate businesses could contain their own unique subdomain of schemas by utilizing individual Apache Kafka® and Schema Registry clusters. In order to copy Kafka topics containing Apache Avro™ data across these environments, an extra process beyond simple topic replication is needed.
Having separate Schema Registry clusters within a company can be a mistake, but when integrating with an external service or company, multiple clusters are sure to exist. Copying schemas to another Schema Registry is possible, although it is not as simple as replicating the underlying schema topic because it may potentially result in overwriting pre-existing schemas within the destination Schema Registry.
In this blog post, we’ll replicate schemas across independent Schema Registry clusters without overwriting any schemas through the help of a custom Kafka Connect Single Message Transform (SMT). The SMT operates on each record as it passes through Kafka Connect and copies schemas located in one Schema Registry cluster to another cluster. At the end, we’ll demo the SMT’s features by using Confluent Replicator configured with the SMT to copy a Kafka topic along with the topic’s schema between unconnected Schema Registry clusters.
Schema Registry: A quick introduction
Schema Registry stores Avro schemas and enforces compatibility rules upon schema updates. It is backed by a compacted Kafka topic, which is consumed into a cache of schemas and is queryable by a REST API. Each schema is stored under uniquely identifiable names called subjects. Each subject can contain multiple versions of a schema, and each version of a schema has a global ID within Schema Registry.
When a Kafka producer is configured to use Schema Registry, a record is prepared to be written to a topic in such a way that the global ID for that schema is sent with the serialized Kafka record. When consumers read this data from Kafka, they look up the schema for that ID from a configured Schema Registry endpoint to decode the data payload. When fully deserialized, the application can then look up fields within the payload. If both the Kafka record’s key and value are Avro encoded, two ID lookups are performed for any given record, one for the key and one for the value. For a diagram of how the producers and consumers interact with Schema Registry, please refer to the schema management documentation.
From the storage perspective, using a simple numeric ID is better than including any textual schema description along with the serialized data for each record. The following image shows what a single Avro-encoded value would look like: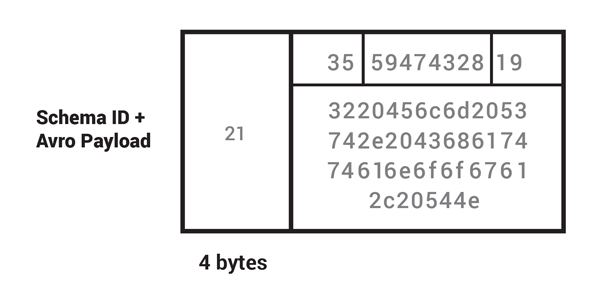
The problem: Replicating topics without overriding schemas
When there are separated Schema Registry clusters, more likely than not, the schemas registered within each will differ. For example, a Schema Registry with an ID of 21 could describe a user profile, yet a schema ID of 21 could exist in another Schema Registry where instead it describes a business transaction.
After replicating a Kafka topic of user-profile records to an environment using that other Schema Registry, the knowledge of which schema ID correctly describes a user-profile is lost. A Kafka consumer reading any replicated user-profile record and configured to use the other Schema Registry will attempt translating the messages into business transactions, as per the original Schema Registry’s ID embedded in the record. The consumption would fail because the business-transaction schema is unable to deserialize user-profile records.
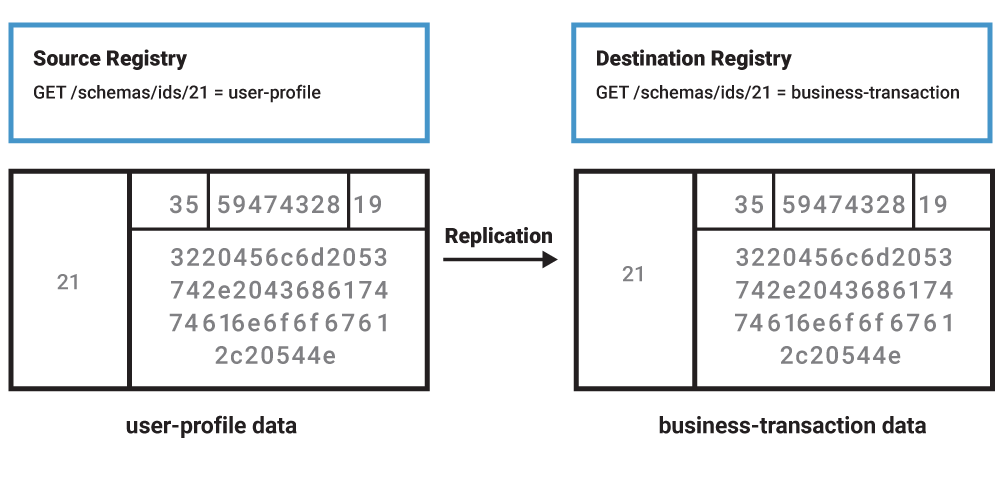
Therefore, an alteration of which ID is associated with the data payload is necessary. Here is an illustration of the required operation after the Kafka record is replicated to an environment with a different Schema Registry cluster. The user-profile schema ID of 21 in the Source Registry is registered to the destination registry as ID 22, and the ID within the record is changed accordingly without modification to the rest of the data payload.
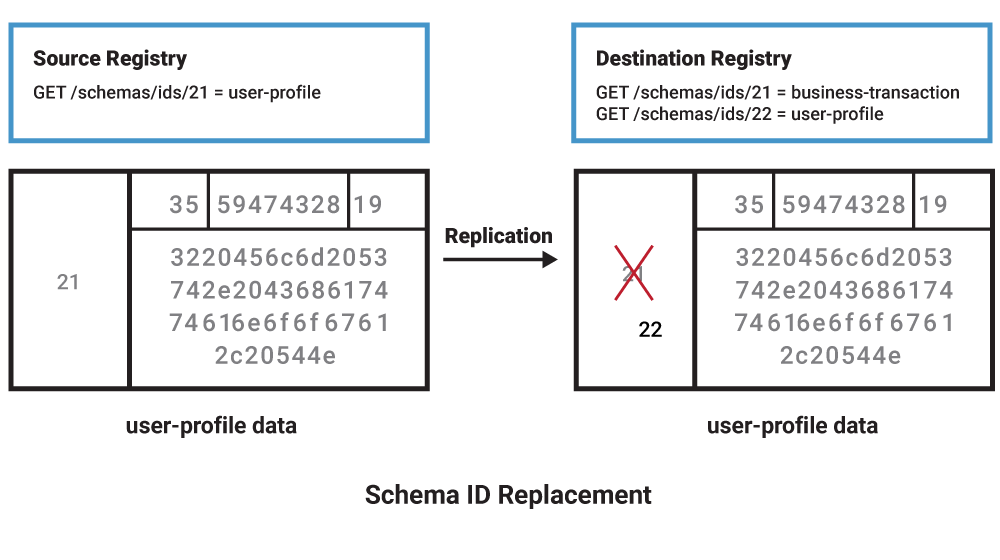 When trying to find a solution to this problem, the recommendations are either to set up a follower Schema Registry in the destination environment or replicate the internal Schema Registry topic over to the destination Kafka cluster. If the destination environment already has a Schema Registry cluster containing schemas, then setting up another Schema Registry just as a follower of the source would be operationally confusing. Additionally, replicating the internal schema topic between environments would corrupt and overwrite any existing schema records since no ID remapping is performed. Therefore, a process that registers new schemas for replicated data between the Schema Registry clusters is required.
When trying to find a solution to this problem, the recommendations are either to set up a follower Schema Registry in the destination environment or replicate the internal Schema Registry topic over to the destination Kafka cluster. If the destination environment already has a Schema Registry cluster containing schemas, then setting up another Schema Registry just as a follower of the source would be operationally confusing. Additionally, replicating the internal schema topic between environments would corrupt and overwrite any existing schema records since no ID remapping is performed. Therefore, a process that registers new schemas for replicated data between the Schema Registry clusters is required.
By using a Kafka Connect SMT within Replicator, the revision of the schema ID can be included alongside the topic’s replication configuration.
Preservation of order
Before demoing the SMT, it is important to call out one caveat with this approach of copying sequential data. Primarily, there isn’t a way to guarantee that schemas are registered in the destination Schema Registry in the exact same order they were registered in the source.
Using the following diagram as an example, given a Kafka partition containing a range of schema IDs, let each incremental value be backwards compatible with the previous one. It is possible that a newer schema in the source cluster is transferred during the replication process before an older schema—this can occur due to retention policies on the topic, for example. The following diagram depicts this scenario, where offsets 0–2 have expired, and offset 3, containing ID 2, is replicated before offset 5, containing ID 1: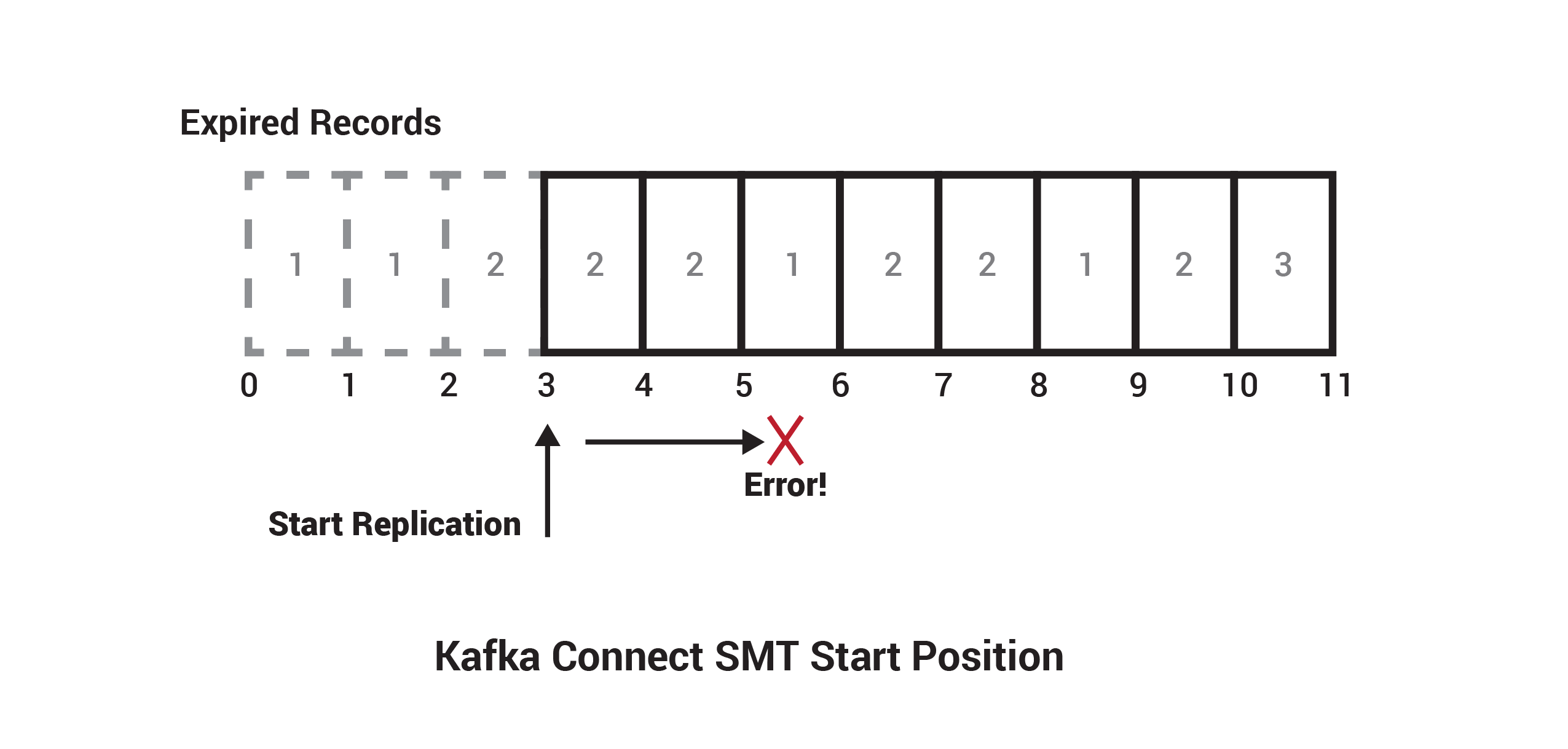
Another scenario where non-sequential IDs are stored in a topic exists when more than one producer application is writing to the topic, where a producer sends lower versioned schemas.
In both scenarios, the transform can fail to register the schemas for the lower IDs because they may not be compatible with the newer ones. A workaround for allowing any ordering of schema registration is to set the compatibility setting to FULL or NONE, as discussed in the schema evolution and compatibility documentation.
Demo architecture
To demonstrate the functionality of this custom SMT, two separate Schema Registry clusters are needed as requests against one are performed in order to get a schema and forward it to another. Each Schema Registry will be configured with the setting master.eligibility=true and use Kafka master election against separate Kafka clusters. This setting indicates that the Schema Registries are independent of one another and therefore each Kafka cluster maintains its own _schemas topic. This is a different deployment scenario than the multi-datacenter setup documentation in which one Schema Registry is set up as a follower to a single master and therefore only one _schemas topic exists in the master. For these settings and more, please refer to the Schema Registry configuration options.
The diagram below depicts the connections involved at a high level. The two dotted blue boxes each represent isolated deployments of Apache ZooKeeper™, Kafka, and Schema Registry, here called “Datacenter A” and “Datacenter B.” The outer orange rectangle represents a network layer capable of connecting a Kafka Connect cluster located in the remote destination of “Datacenter B” with both the Schema Registry and Kafka clusters located in “Datacenter A.” Producers, consumers, and other Confluent Platform components are not depicted here for simplicity, though each would ideally be located within the network boundaries of their respective local Kafka brokers and Schema Registries rather than reaching in from outside, in order to ensure an optimal connection.
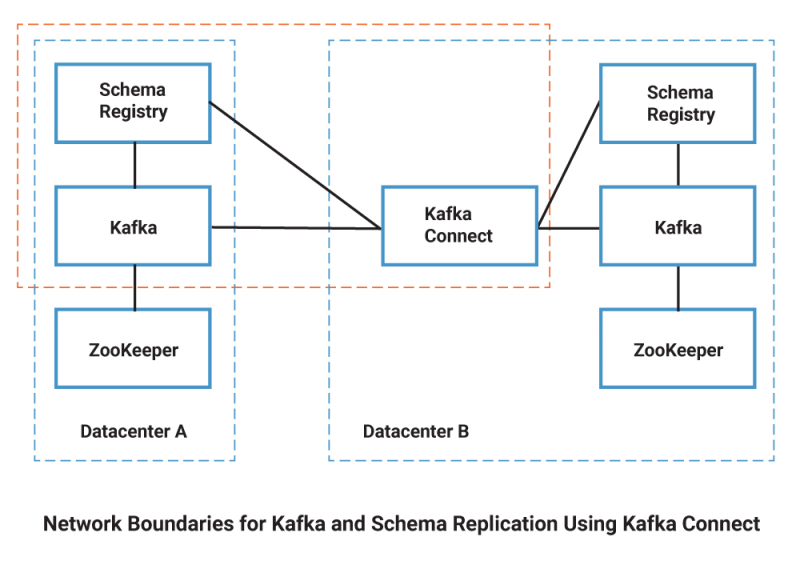
Order of operations
As mentioned earlier, when a producer is configured with the Schema Registry Avro serializer, the schema is replaced with a computed ID from the Schema Registry. This ID is then prepended to the serialized Avro data before being sent to Kafka. The advantage of Kafka Connect is that it wraps the same producer and consumer APIs, meaning the records can be transformed using the SMT code into a format that downstream Kafka consumers can process.
Keeping with the isolated deployments above for the source Schema Registry in Datacenter A and destination Schema Registry in Datacenter B, the following diagram illustrates the order of operations for the SMT code:
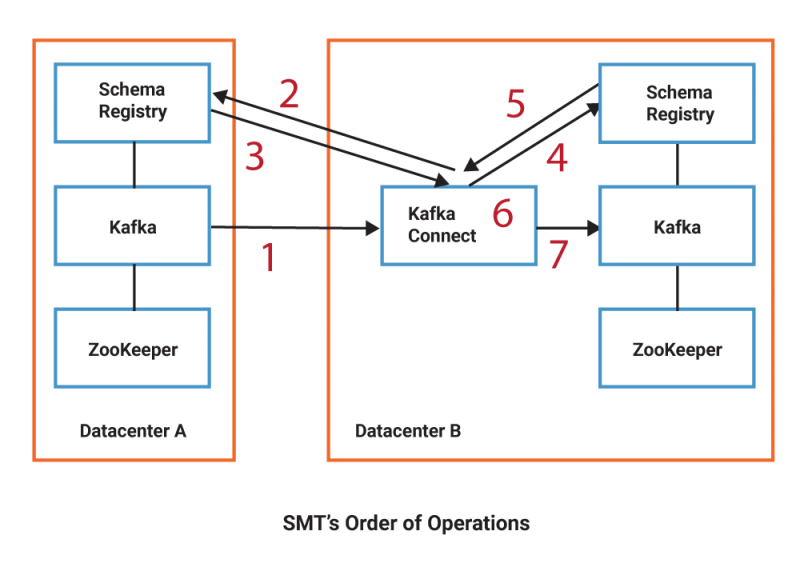
- A Kafka Connect task consumes a Kafka record from Datacenter A as bytes
- The transform is applied, looking up the embedded schema ID of the record within the source Schema Registry in Datacenter A
- The Avro schema text is returned to the transform method
- The Avro schema text is registered against the destination Schema Registry in Datacenter B
- The destination Schema Registry in Datacenter B returns the schema ID
- The ID is updated inside the Kafka record without modifying the original Avro payload
- The transformed record is sent to Kafka in Datacenter B
SMT demonstration
To showcase the features of the SMT, a Docker runbook has been prepared that will start two isolated Confluent Platform clusters, which are linked only by Kafka Connect, matching the above demo architecture. The kafka-avro-console scripts are used to produce Avro messages in the source cluster while Replicator replicates records to the destination. Then, a consumer is used to inspect the changes in the Avro schema ID as the schema is updated by a producer.
Prerequisites
- Ensure an internet connection
- Install Docker to run the example
The transformation can be downloaded from GitHub. This file will need to be copied into the plugin.path directory of each Kafka Connect worker.
The configured environment can be checked out from GitHub:
$ git clone https://github.com/cricket007/kafka-connect-sandbox.git $ cd kafka-connect-sandbox/replicator
Before starting the project, increase the memory dedicated to Docker in advanced settings to at least 8 GB (default is 2 GB) given the number of processes required to run the demo. After these steps are completed, go ahead and start up the demo:
$ docker-compose up -d
Run each of the following commands will within the Kafka Connect Docker container for simplicity:
$ docker-compose exec kafka-connect bash
1. If you’re a new Kafka user, first create a topic:
$ kafka-topics --create --topic topic-a \ --bootstrap-server kafka-a:9092 \ --partitions=1 --replication-factor=1
2. Produce data to simulate pre-existing topic data that will be replicated:
$ /scripts/0_Produce_Records_v1.sh kafka-a:9092 topic-a http://schema-registry-a:8081
3. Replicate the data by posting a Kafka Connect configuration to its API. This will replicate topic-a to topic-a.replica by using Confluent Replicator. The configuration of the connector will be displayed as a response:
$ /scripts/1_POST-replicator.sh
4. Verify that the topic was created in the destination cluster and the Schema Registry _schemas topic exists there as well:
$ kafka-topics --list --bootstrap-server kafka-b:9092 ... _schemas # <<< here is the destination Schema Registry topic topic-a.replica # <<< here is the newly created topic
5. Read the topic.
Now that the topic has been replicated, consumers existing in Datacenter B should be able to read that data. However, since the schema is not copied to the destination Schema Registry, an error is observed while consuming:
$ kafka-avro-console-consumer \ --bootstrap-server kafka-b:9092 \ --topic topic-a.replica \ --property schema.registry.url=http://schema-registry-b:8081 \ --from-beginning
Processed a total of 1 messages [2019-08-11 22:17:42,078] ERROR Unknown error when running consumer: (kafka.tools.ConsoleConsumer$:76) org.apache.kafka.common.errors.SerializationException: Error retrieving Avro schema for id 1 Caused by: io.confluent.kafka.schemaregistry.client.rest.exceptions.RestClientException: Schema not found; error code: 40403
The Schema not found error is expected because there is no configuration to reference Schema Registry B in Replicator’s posted configuration; therefore, it has no subjects or schemas, as shown when contacting its API:
$ curl http://schema-registry-b:8081/subjects []
6. Update the connector config to include the transform.
In order for Replicator to know how to transfer schemas, a few properties need to be added to apply the SMT, starting with the transforms property. These include, at a minimum, the type of transform in addition to two required properties for the source and destination Schema Registry endpoints. Other configurations can be added, such as the option not to copy the schema for the Kafka record keys, or including HTTP authorization. Refer to the SMT’s README for additional configurations. For simplicity, record keys and HTTPS configurations are excluded from this post.
$ /scripts/2_PUT-update-replicator-with-transform.sh
In the script output, notice that the following section of configurations have been added that include the source and destination Schema Registry URLs:
"transforms": "AvroSchemaTransfer", "transforms.AvroSchemaTransfer.type": "cricket.jmoore.kafka.connect.transforms.SchemaRegistryTransfer", "transforms.AvroSchemaTransfer.transfer.message.keys": "false", "transforms.AvroSchemaTransfer.src.schema.registry.url": "http://schema-registry-a:8081", "transforms.AvroSchemaTransfer.dest.schema.registry.url": "http://schema-registry-b:8081"
7. Produce another message with the same schema.
Once Replicator has been updated with the SMT configurations, it then knows how to transfer schemas upon receiving new messages. The Produce_Records script is run again to create records similar to those in step 2 and transfer their schema via the transform. This is needed because records that were already replicated did not have the transform applied to them. When replicating a topic that is actively produced to, this step is seamless.
$ /scripts/0_Produce_Records_v1.sh kafka-a:9092 topic-a http://schema-registry-a:8081
8. Re-run the consumer to verify that the topic can now be read from the beginning:
$ kafka-avro-console-consumer \ --bootstrap-server kafka-b:9092 \ --topic topic-a.replica \ --property schema.registry.url=http://schema-registry-b:8081 \ --from-beginning \ --property print.schema.ids=true
The expected output looks like the following, containing the timestamp of when the record was produced and a string field describing the record. The 1 at the end is the schema ID in the Schema Registry for these record values.
{"time":1571366837560,"desc":"record at 1571366837560"} 1
{"time":1571366837562,"desc":"record at 1571366837562"} 1
{"time":1571366837564,"desc":"record at 1571366837564"} 1
{"time":1571366837566,"desc":"record at 1571366837566"} 1
Additionally, the destination Schema Registry now contains a subject and version for the replicated topic:
$ curl http://schema-registry-b:8081/subjects ["topic-a.replica-value"]
$ curl http://schema-registry-b:8081/subjects/topic-a.replica-value/versions/ [1]
9. Change the schema in a compatible manner.
As the source topic is modified and producers change schemas in a compatible way enforced by the source Schema Registry, those changes are also replicated to the destination via the SMT. A new producer script can be run to demonstrate that behavior:
$ /scripts/3_Produce_Records_v2.sh kafka-a:9092 topic-a http://schema-registry-a:8081
Upon successful replication, the destination Schema Registry has a new version:
$ curl http://schema-registry-b:8081/subjects/topic-a.replica-value/versions/ [1, 2]
Consuming again and scrolling through the output reveal that there are now different record objects containing a counter field, and the new schema ID of those records is 2.
$ kafka-avro-console-consumer \ --bootstrap-server kafka-b:9092 \ --topic topic-a.replica \ --property schema.registry.url=http://schema-registry-b:8081 \ --from-beginning \ --property print.schema.ids=true
{"time":1571366837564,"desc":"record at 1571366837564"} 1 {"time":1571366837566,"desc":"record at 1571366837566"} 1 {"time":1571367696421,"desc":"record at 1571367696421","counter":1} 2 {"time":1571367696423,"desc":"record at 1571367696423","counter":2} 2
The above steps show how to transfer schemas between empty Schema Registries, meaning the IDs in each Schema Registry are the same. The real power of the transform is that it will generate a new schema in the destination when there is a collision. To demonstrate this feature, a new schema with the ID of 3 will be generated first in the destination Schema Registry.
$ /scripts/gen_schema.sh http://schema-registry-b:8081 new-subject 1
$ curl http://schema-registry-b:8081/subjects/new-subject/versions/1
{"subject":"new-subject","version":1,"id":3,"schema": "..."}
The third version of topic-a (with the ID of 3) in the source Schema Registry is created by producing records with a newer schema:
$ /scripts/4_Produce_Records_v3.sh kafka-a:9092 topic-a http://schema-registry-a:8081
When comparing the replicated topic’s subject in each Schema Registry, the included IDs are different for the same version of the schema:
$ curl http://schema-registry-a:8081/subjects/topic-a-value/versions/3
{"subject":"topic-a-value","version":3,"id":3,"schema":"..."}
$ curl http://schema-registry-b:8081/subjects/topic-a.replica-value/versions/3
{"subject":"topic-a.replica-value","version":3,"id":4,"schema":"..."}
Consumption of the topic again shows the following:
{"time":1571373117957,"desc":"record at 1571373117957","counter":1,"remaining":{"int":19}} 4
If the SMT configuration is removed from Replicator such that the schema ID is not updated, the following error is encountered in this example when consuming the messages. The error indicates that the schema returned from the Schema Registry for the consumed message was unable to be used for deserializing the record payload:
[2019-10-18 04:37:33,091] ERROR Unknown error when running consumer: (kafka.tools.ConsoleConsumer$:76) org.apache.kafka.common.errors.SerializationException: Error deserializing Avro message for id 3 Caused by: java.io.IOException: Invalid int encoding
Conclusion
By using the SMT, you can selectively transfer schemas between separate Schema Registry clusters alongside Kafka topic data while both renaming those topics and keeping the schemas in sync in a multi-datacenter environment. Schema Registries also do not require an active-passive configuration and can be shared across multiple Schema Registry clusters without the potential for schema ID collisions.
The SMT in this blog post facilitates the majority of today’s use cases and has been running in production. Progress towards copying schemas in a non-backwards-compatible manner without pre-configuration of the config endpoints of Schema Registry as well as support for topics with multiple event types are being tracked via the GitHub repository.
If you’d like to know more, you can download the Confluent Platform to get started with Schema Registry as part of a complete event streaming platform built by the original creators of Apache Kafka.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...