[Webinar] Harnessing the Power of Data Streaming Platforms | Register Now
I’ve Got the Key, I’ve Got the Secret. Here’s How Keys Work in ksqlDB 0.10.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
ksqlDB 0.10 includes significant changes and improvements to how keys are handled. This is part of a series of enhancements that began with support for non-VARCHAR keys and will ultimately end with ksqlDB supporting multiple key columns and multiple key formats, including Avro, JSON, and Protobuf.
Before looking at the syntax changes in version 0.10, let’s first look at what is meant by keys in ksqlDB, the two types of key columns, and how this may differ from other SQL systems.
What’s with all these keys then?
There are two types of primary objects in ksqlDB: tables and streams. They handle keys in different ways:
- Tables in ksqlDB have a PRIMARY KEY, much like tables in any other SQL system. The primary key defines the unique identity of a row within the table. Rows in a table are inserted, updated, or deleted as input events are processed. As of version 0.10, ksqlDB supports a single column in a table’s primary key, and that column value must be non-NULL.
- Streams do not have primary keys. Each row within a stream is treated as an independent, immutable fact: Rows in a stream are never updated. While streams do not have PRIMARY KEYs, they can declare a single column as a KEY column. More on stream KEY columns below.
A table’s primary key column and a stream’s key column are both collectively referred to as key columns.
How are tables and streams persisted in ksqlDB?
Both tables and streams are stored in topics in Apache Kafka®. In the case of tables, the Kafka topic acts as the changelog for modifications to the table. To dive deeper into the duality between a table and its changelog stream, take a look at Streams and Tables in Apache Kafka: A Primer.
Records in all Kafka topics have a key-value model, and the key plays an important role in determining partitioning, compaction, and ordering guarantees. The primary key of a table’s row, and only the primary key, is stored within the Kafka record’s key. This ensures all updates to a specific key are contained within the same partition of the topic, compaction only retains the last record per key, and the order of updates to a key is maintained. This is crucial if the changelog is to be materialized back into a table.
While the materialized table in ksqlDB can contain only a single row for any specific primary key, the changelog topic that backs a table often contains multiple records with the same key, as row values change over time. A later record value replaces the existing record value. The changelog topic can also contain records with a null value. Such records are known as tombstones and indicate a logical deletion of the row from the table.
If a table’s primary key maps directly to the key in the table’s changelog topic records, then what about streams? Though they don’t have primary keys, surely there’s no reason why they shouldn’t be able to access or store data in the Kafka record’s key, right? A record’s key is an important and powerful primitive in Kafka and is not something ksqlDB should be abstracting. This is why ksqlDB streams can define KEY columns. Declaring a column as a KEY column indicates that the data for the column is loaded from the Kafka record’s key, not its value. It does not infer any unique or non-null attributes of the data itself, as a primary key would.
| ℹ️ | It’s worth saying this for a second time, as this is an important point about key columns: Declaring a column as a KEY or PRIMARY KEY column indicates that the data for the column is loaded from the Kafka record’s key, not its value. |
Why have a stream with a key column?
ksqlDB is a distributed system and work may be carried out over multiple nodes, depending on how the Kafka topic is partitioned. Before ksqlDB can perform certain operations on your data, for example, aggregations and joins, it first needs to ensure that the data is correctly partitioned to ensure that associated rows are processed by the same task within the ksqlDB cluster. Take, for example, a simple aggregation:
SELECT id, COUNT(*) FROM my_stream GROUP BY id;
To be able to compute the count of rows per id efficiently, ksqlDB requires the data to be partitioned by id, that is, all rows with the same id must be in the same partition before the final processing takes place.
Why? Imagine if the rows for an id were spread across all the partitions; to calculate the total result, either a single ksqlDB cluster member would need to consume all the rows and keep a single count, or the rows could be distributed across the cluster and the results somehow merged. Both of these approaches would seriously degrade the scalability, performance, and efficiency of ksqlDB.
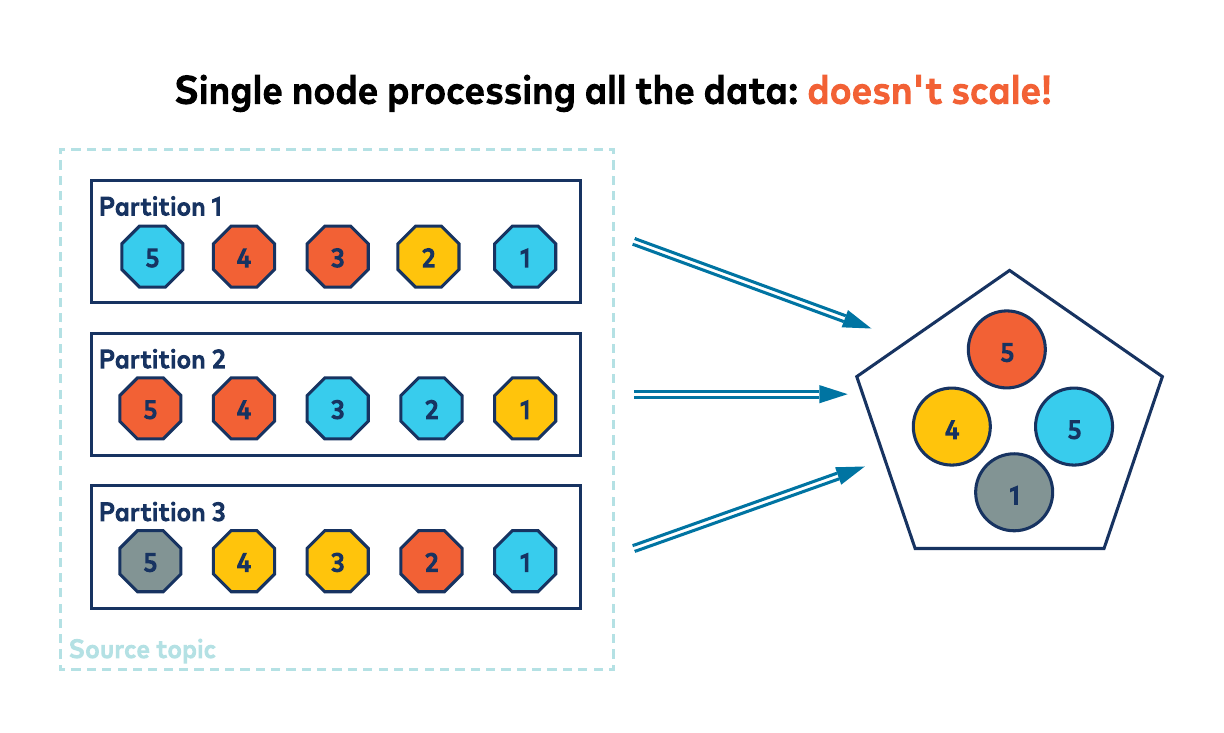
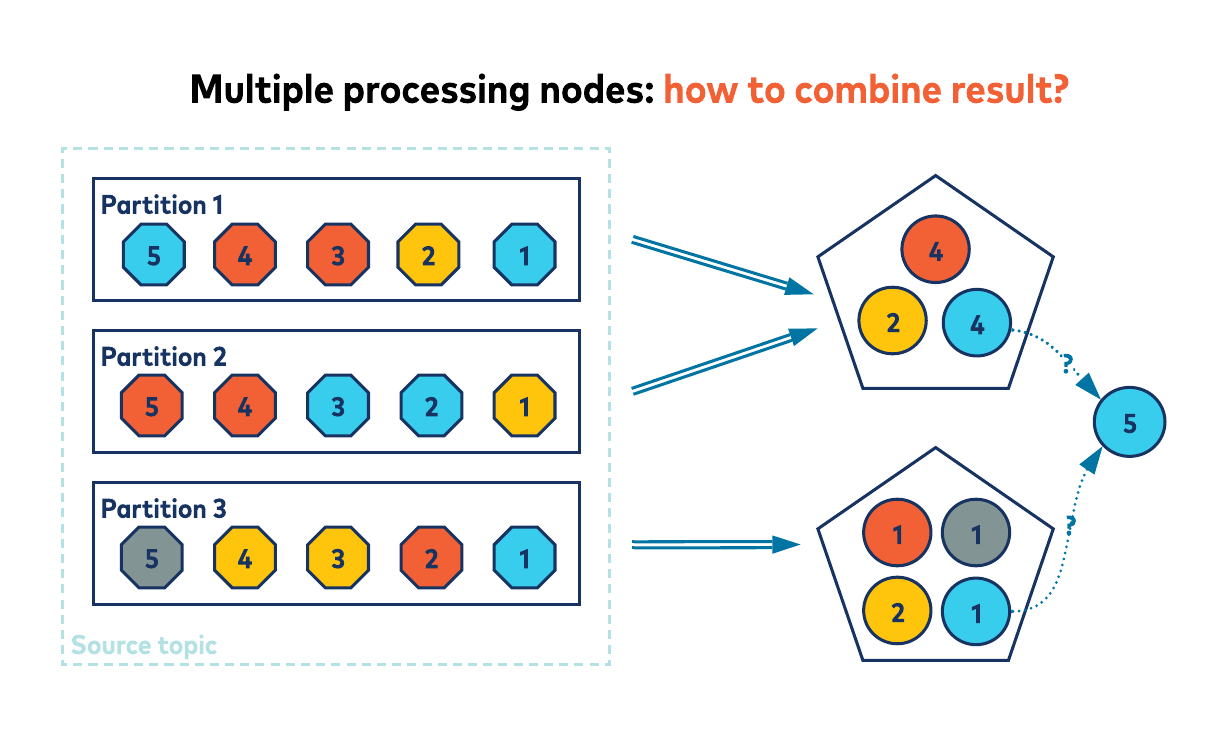
If the data in my_stream‘s topic is not already partitioned by id (that is, id is not the record key in the topic), then ksqlDB must first repartition your data for you. This repartitioning involves reading each record from the source topic and producing the record back to an internal repartition topic, with the record’s key now set to id. Knowing the rows are correctly partitioned, ksqlDB can quickly and efficiently keep running counts per key as it processes your data.
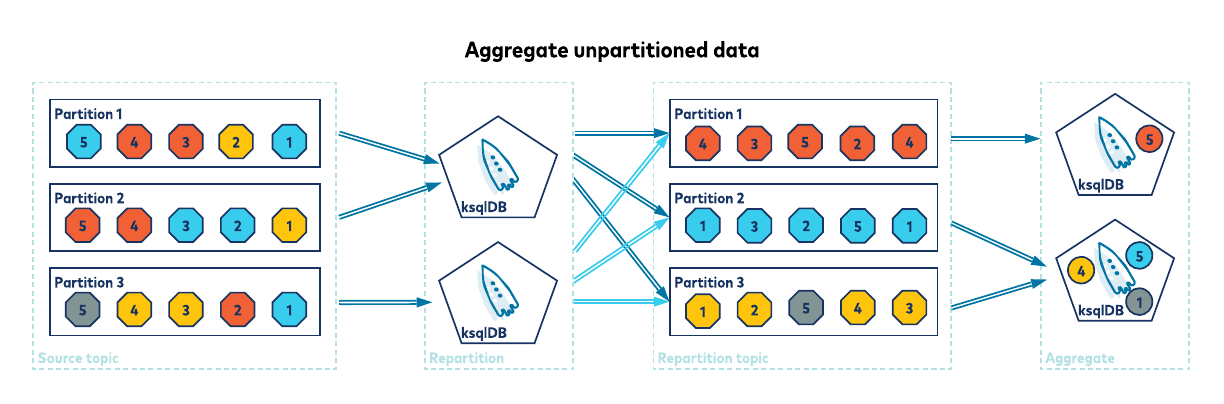
Duplicating your data into an internal repartition topic has a cost, both in terms of latency and resources. This cost can be avoided if the rows are already correctly partitioned. If the record’s key holds the id (and thus id is the stream’s KEY column), the rows will be correctly partitioned by default.
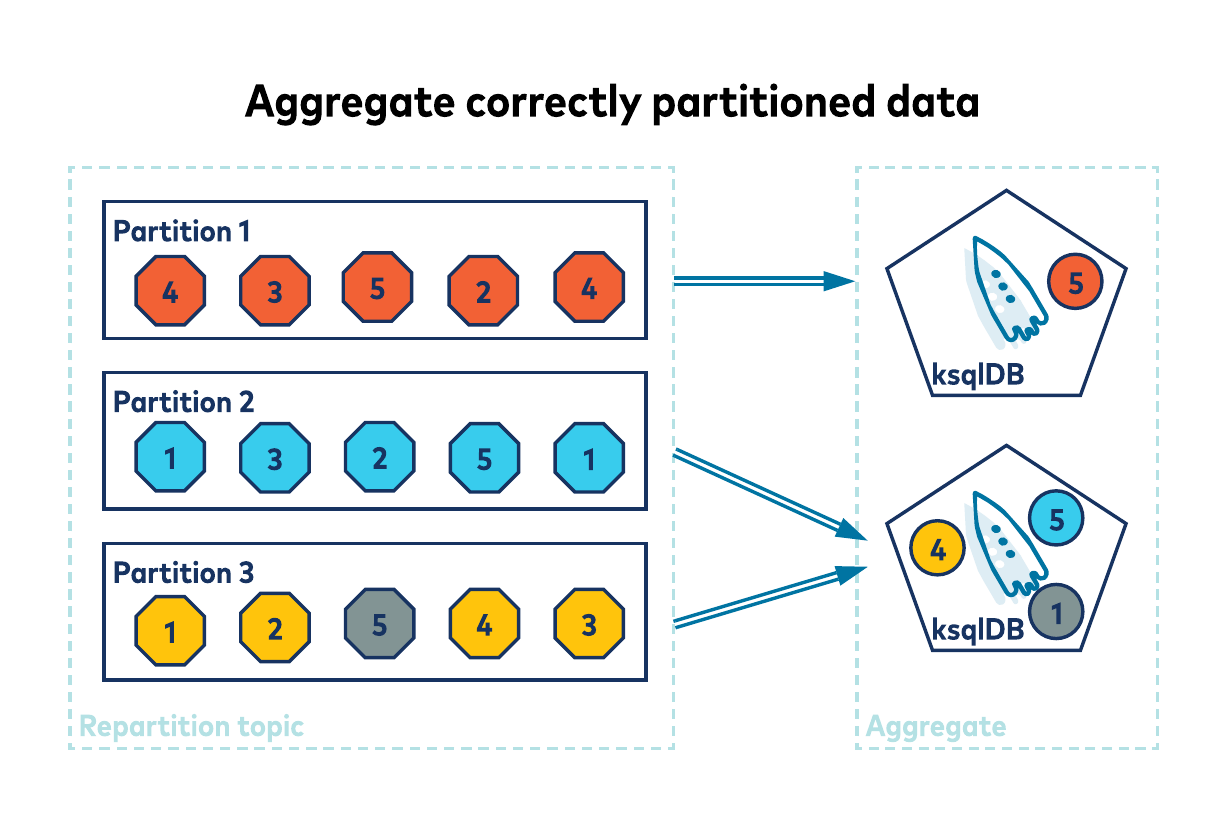
As you can see, having correctly partitioned data is important when building aggregates. It’s also important when performing joins. For joins to work, not only must your data be correctly partitioned but also both sides of the join must have a matching number of partitions. This is necessary to ensure rows from both sides of a join, with the same key, go to the same processing node to facilitate the join. As with GROUP BY, ksqlDB may internally repartition the data to enable a join. This co-partitioning is key (sorry, bad pun), to getting your join to work. You can read more about it in the Partitioning Requirements page for joins on the ksqlDB microsite.
Key column recap
To recap, there are two types of key columns. Tables have primary keys, which map to the data in the key of the Kafka record. A primary key is unique and must be non-null. Streams have key columns, which also map to the data in the key of a Kafka record but don’t infer any unique or non-null attributes of the data itself. Having correctly keyed data can save ksqlDB from performing additional steps, reducing latency and resource utilisation.
WITH KEY = WITH CONFUSION
In ksqlDB versions prior to the 0.10 release, all tables and streams in ksqlDB had a key column named ROWKEY. If you did not declare a key column when declaring a table or stream, the system automatically added one of type VARCHAR. For example, the users table created in the statement below would have an implicit ROWKEY VARCHAR primary key column:
CREATE TABLE users (
id VARCHAR
name VARCHAR
) WITH (
KAFKA_TOPIC='users',
VALUE_FORMAT='json'
);
You were also free to explicitly define the type, if not the name, of the key column in the statement. This was required if the type was anything other than VARCHAR:
CREATE TABLE users (
rowkey BIGINT PRIMARY KEY
id VARCHAR
name VARCHAR
) WITH (
KAFKA_TOPIC='users',
VALUE_FORMAT='json'
);
Optionally, you could set the KEY property in the WITH clause to the name of a value column that contained the same data as the Kafka record’s key, which is the same data as ROWKEY.
CREATE TABLE users (
rowkey BIGINT PRIMARY KEY
id BIGINT
name VARCHAR
) WITH (
KAFKA_TOPIC='users',
VALUE_FORMAT='json',
KEY='ID' -- ID column is an alias for ROWKEY column
);
The main benefit was the ability to use a more descriptive name for the key column in your queries while avoiding unnecessary and costly repartitions of your data. The column you identified in the WITH clause acted as an alias to the ROWKEY column. The following is an example join of a purchases stream to the users table on user Id:
SELECT *
FROM purchases
JOIN users ON purchases.userId = users.id;
It is much easier on the eye and easier to understand than the same query using ROWKEY:
SELECT *
FROM purchases
JOIN users ON purchases.userId = users.rowkey;
Unfortunately, using this pattern requires duplication of the Kafka record key’s data into the record’s value. The Kafka record’s key/value from the users changelog topic might look like this, for instance:
26543: {"ID": 26543, "NAME": "bob"}
Notice the user Id of 26543 is duplicated in both the key and value of the Kafka record. This wastes resources and isn’t always practical or achievable. It also causes a great deal of wailing and gnashing of teeth since the syntax was more of a hint than an instruction to ksqlDB. For data that looked like this (notice the key 42 does not match the Id of 26543):
42: {"ID": 26543, "NAME": "bob"}
…ksqlDB would not change the record key that it used in its join condition. Thus, joins, which should apparently work (“but I have an event on the left side of the join with a matching value of 26543—why don’t I get a result back?”), would fail.
Changes to keys in ksqlDB 0.10: Call your keys what you want!
Implicit ROWKEY columns and the WITH(key='ID') syntax have caused a lot of confusion in the community. The WITH(key='ID') syntax is something we’ve been working to remove, since it’s not the most appropriate semantic abstraction to describe how to model the data. To allow us to remove it and the need to duplicate the key’s data into the value, the 0.10 release of ksqlDB allows you to name your key columns whatever you like!
| ℹ️ | ksqlDB is developed in the open, with the community, and we use KLIPs (KsqLdb Improvement Proposals) to explore and propose API changes. Check out KLIP-25 for the discussion behind the removal of the WITH(key='ID') syntax, KLIP-24 for the changes to key handling semantics in queries, KLIP-29 for the removal of the implicit ROWKEY key column, or the ksqlDB project on GitHub for more proposals and get involved! |
Declaring a users table with a BIGINT primary key can now be rewritten as:
-- new syntax for creating a table:
CREATE TABLE users (
id BIGINT PRIMARY KEY,
name VARCHAR
) WITH (
KAFKA_TOPIC='users',
VALUE_FORMAT='json'
);
And the corresponding data in Kafka no longer requires data duplication:
26543: {"NAME": "bob"}
I hope you agree that this is a little cleaner and clearer! It is important to note that the name you give your key columns in ksqlDB isn’t yet persisted anywhere, other than in ksqlDB’s own internal metastore. How so? Well, at present, ksqlDB supports a single primitive key column serialized using the KAFKA format, and this format only serializes the data within the column (not the column name), and it does not integrate with the Confluent Schema Registry. Future versions of ksqlDB will offer full support for key formats that do store field names, such as Avro/Protobuf/JSON Schema (using the Schema Registry) or JSON (with embedded field names).
Keyless streams
While giving you the freedom to define the name of your key columns, it also made sense to tighten up when a key column should be defined. As already mentioned, previous versions would add an implicit ROWKEY VARCHAR key column if none was declared.
As discussed above, streams don’t logically require a key column. To support this, ksqlDB no longer adds an implicit key column if you don’t declare one: No key column declared means your stream has no key column. Simple. Any data in the key will be ignored. Of course, this may mean you’ll pay the cost of repartitions should you later need to join or aggregate the stream. So it pays to think carefully about whether you should have a key column or not.
How do you know if you need a key column for your stream? Well, you probably don’t need a key column if any of the following statements are true:
- There is no data stored in the Kafka record’s key.
- You are not interested in the data stored in the Kafka record’s key.
- The data stored in the Kafka record’s key is not in a format ksqlDB can read.
If you do want a key column for your stream, then you must make sure that the key part of the Kafka message is appropriately populated. Just as with the WITH KEY confusion before, you cannot pick an arbitrary field from the value part of the message and denote this as the key.
Here’s an example of the new syntax for creating a stream with no key column:
CREATE STREAM purchases (
purchaseId BIGINT,
productId BIGINT,
price DECIMAL(10, 2),
quantity INT
) WITH (
KAFKA_TOPIC='purchases',
VALUE_FORMAT='json'
);
If we were to insert some values into this stream:
INSERT INTO purchases VALUES (10, 101, 2.30, 2);
…the corresponding Kafka message would have a null key, and all the columns would be defined in the value:
null : {"purchaseId": 10, "productId": 101, "price": 2.30, "quantity": 2}
Let’s contrast the above example with one where the purchaseId column is stored in the Kafka record’s key:
CREATE STREAM purchases (
purchaseId BIGINT KEY,
productId BIGINT,
price DECIMAL(10, 2),
quantity INT
) WITH (
KAFKA_TOPIC='purchases',
VALUE_FORMAT='json'
);
-- Same insert statement:
INSERT INTO purchases VALUES (10, 101, 2.30, 2);
This time, the Kafka records key/value looks like this:
10 : {"productId": 101, "price": 2.30, "quantity": 2}
Notice that the value has no purchaseId field this time, because the value of purchaseId is stored in the key.
What about tables? Can you have keyless tables? No, the key is needed to support the insert, update, and delete semantics of rows in the table. Since tables always require a primary key, in ksqlDB 0.10, you’ll see an error if you try to create a table without one:
ksql> CREATE TABLE USERS (ID BIGINT, NAME VARCHAR)
WITH(KAFKA_TOPIC='users', PARTITIONS=1, VALUE_FORMAT='json');
Tables require a PRIMARY KEY. Please define the PRIMARY KEY.
Keys and the Schema Registry
If you’re using a serialisation format that integrates with the Schema Registry (Avro/Protobuf/JSON Schema), you will be used to the joyful experience of declaring a stream or table by just specifying the object name, value format and source topic, and the schema being picked up automagically:
ksql> CREATE STREAM purchases
WITH (KAFKA_TOPIC='purchases', VALUE_FORMAT='Avro');
ksql> DESCRIBE purchases;
Name : PURCHASES
Field | Type
----------------------------------------------
PURCHASEID | BIGINT
PRODUCTID | BIGINT
PRICE | DECIMAL(10,2)
QUANTITY | INTEGER
----------------------------------------------
If you want to specify a key alongside a schema picked up automagically from the Schema Registry, specify the key on its own, like this:
ksql> CREATE STREAM purchases (ID BIGINT KEY)
WITH (KAFKA_TOPIC='purchases', VALUE_FORMAT='Avro');
ksql> DESCRIBE purchases;
Name : PURCHASES
Field | Type
---------------------------------------------
ID | BIGINT (Key)
PURCHASEID | BIGINT
PRODUCTID | BIGINT
PRICE | DECIMAL(10,2)
QUANTITY | INTEGER
---------------------------------------------
The above statement declares a purchases stream with an explicitly declared key column, and the value columns are loaded from the Schema Registry. This is called partial schema inference. Future versions of ksqlDB will support key formats that integrate with the Schema Registry, allowing the key column definitions to also be loaded automatically.
Query semantics changes
There are some other changes that fall out of derestricting the naming of key columns, which were implemented by KLIP-24 and are discussed below.
Materialized view key columns
The key column in any materialized views you create from other sources, i.e., CREATE TABLE AS SELECT and CREATE STREAM AS SELECT statements, changes with version 0.10.
Aggregations
For example, in an aggregation such as:
CREATE TABLE products_sold AS
SELECT
productId,
SUM(quantity) as totalQty
FROM purchases
GROUP BY productId;
…the key column of the products_sold table will be called PRODUCTID instead of the default ROWKEY of previous versions.
In a similar way, grouping by a single STRUCT field results in a key column with the name, type, and content of the field you grouped by. For example, the following results in a key column called ID:
CREATE TABLE products_sold AS
SELECT
product->id,
SUM(quantity) as totalQty
FROM purchases
GROUP BY product->id;
Grouping by anything else adds a new column, with a system-generated column name. For example, the following has a key column called KSQL_COL_0. (See below for how you can provide your own name for the key column.)
CREATE TABLE users AS
SELECT
LCASE(address->country),
COUNT() as count
FROM users
GROUP BY LCASE(address->country);
Key columns in projections
Any readers familiar with older versions of ksqlDB may have looked at the above aggregation and assumed that the LCASE(address->country) in the projection would mean the lowercase country would be stored in the Kafka message’s value (as well as the key), and for older versions, you would have been right!
Unlike older versions, ksqlDB 0.10 now requires you to include the full set of columns, including the key column, in the projection when creating a materialized view. If you don’t include the key in the projection, you’ll get an error:
CREATE TABLE users AS
SELECT
COUNT() as count
FROM users
GROUP BY LCASE(address->country);
Key missing from projection. The query used to build users must include the grouping expression LCASE(address->country) in its projection.
When you add the key column to the projection, you can also choose to provide an alias if you want to change its name:
CREATE TABLE users AS
SELECT
LCASE(address->country) as country,
COUNT() as count
FROM users
GROUP BY LCASE(address->country);
Remember, the key column is now only stored in the Kafka record’s key. So an example record in the above table’s changelog topic might be "narnia" : {"COUNT": 101}. This is different from previous versions, where the country would be duplicated in the value: "narnia" : {"COUNTRY": "narnia", "COUNT": 101}.
If you actually need a copy of the key column in the value, such as to keep the output the same as a previous version of ksqlDB, then you’ll need a way of letting ksqlDB know that’s your intent. The new AS_VALUE function allows you to express that intent:
CREATE TABLE users AS
SELECT
LCASE(address->country) as rowkey,
AS_VALUE(LCASE(address->country)) as country
COUNT() as count
FROM users
GROUP BY LCASE(address->country);
The changelog topic’s Kafka record will then contain a copy of the key in the value: "narnia" : {"COUNTRY": "narnia", "COUNT": 101}.
Multi-column aggregations
One edge case of note is grouping by more than one expression:
CREATE TABLE products_by_sub_cat AS
SELECT
categoryId,
subCategoryId
SUM(quantity) as totalQty
FROM purchases
GROUP BY categoryId, subCategoryId;
In the above statement, the primary key of the products_by_sub_cat table should contain both the categoryId and subCategoryId columns, and it does…kind of 😉
Until we add multiple key column support, the two columns are combined into a single key column with a system-generated name. ksqlDB essentially runs this query for you:
CREATE TABLE products_by_sub_cat AS
SELECT
CAST(categoryId AS STRING)
+ '|+|'
+ CAST(subCategoryId AS STRING),
SUM(quantity) as totalQty
FROM purchases
GROUP BY CAST(categoryId AS STRING)
+ '|+|'
+ CAST(subCategoryId AS STRING);
If you want to provide an alias for the key column in ksqlDB 0.10, you can’t do so using the default GROUP BY exp1, exp2 syntax. A workaround is to handle the column concatenation yourself and de-concatenate it when needed, as shown here:
-- This uses the arbitrary character § to separate fields. Use a different character
-- if this character appears in your data. (Yes, this is a hack).
CREATE TABLE products_by_sub_cat AS
SELECT
CAST(categoryId AS STRING)
+ '§'
+ CAST(subCategoryId AS STRING) AS compositeKey
SUM(quantity) as totalQty
FROM purchases
GROUP BY
CAST(categoryId AS STRING)
+ '§'
+ CAST(subCategoryId AS STRING);
SELECT
SPLIT(compositeKey,'§')[0] AS categoryId,
SPLIT(compositeKey,'§')[1] AS subCategoryId,
totalQty
FROM products_by_sub_cat
EMIT CHANGES;
Repartitions
The key column of a statement including a PARTITION BY clause is resolved in much the same way as for GROUP BY.
CREATE STREAM purchases_by_user AS
SELECT *
FROM purchases
PARTITION BY userId;
The above results in a products_by_user stream with the userId column as the key column. If the purchases stream has an existing key column, it will become a value column in purchases_by_user. To put this another way, the query is selecting all columns from the source with its SELECT *, so the result will contain all of the source’s columns. The only change is that the userId column is now the key column.
Joins
The final area affected are JOINs. The key column in the result of any join, other than a FULL OUTER join, will be the leftmost join column. If the leftmost join expression is not a simple column reference (i.e., anything other than a single column name), then the next leftmost join expression is evaluated. If no join expressions are simple column references, or if the join is a FULL OUTER join, then ksqlDB introduces a synthetic key column.
Let’s take that a step at a time. First, let’s look at a simple join of two sources, joining on a column from each source:
CREATE STREAM enriched_purchases AS
SELECT *
FROM purchases
JOIN products ON purchases.productId = products.id;
The leftmost join expression, purchases.productId, is a simple column reference, so the enriched_purchases stream will have the purchases.productId column as its key column and all other columns as value columns.
What would happen if the leftmost expression wasn’t a simple column reference?
CREATE STREAM enriched_purchases AS
SELECT *
FROM purchases
JOIN products ON purchases.productId + 1 = products.id;
OK, this is a slightly contrived example, but maybe the IDs between these two sources are off by one. As the leftmost join expression, purchases.productId + 1 is no longer a simple column reference. It cannot become the key column of the result, so the next leftmost expression, products.id, will become the key column of enriched_purchases.
What if no join expressions are simple column references, or what if the join is a FULL OUTER JOIN? In such situations, ksqlDB is unable to use a column from a source as the key column of the result. To understand why, let’s look at a FULL OUTER join:
CREATE STREAM purchase_shipments AS
SELECT *
FROM purchases
FULL OUTER JOIN shipments
WITHIN (0 SECONDS, 1 HOUR)
ON purchases.purchaseId = shipments.purchaseId;
Because the join is a FULL OUTER JOIN, either side of the join might be missing, meaning the output will include purchases without matching shipments, shipments without matching purchases, and, of course, purchases with matching shipments.
If either side of the join can be missing, then for any output row, either purchases.productId or products.id may be null. To ensure the output always has the correct key, ksqlDB uses the first non-null value obtained from evaluating the join expressions as the key of the result.
| purchase.purchaseId | shipments.purchaseId | key of purchase_shipments |
| 108 | 108 | 108 |
| 42 | NULL | 42 |
| NULL | 19 | 19 |
This means that the key of the result does not match either the purchases.productId or products.id columns, so neither of these can be the key column of the result. The key column in the result is a new column created as an artifact of the current join implementation. The new synthetic key column will be given a system-generated name, ROWKEY, by default:
ksql> DESCRIBE purchase_shipments;
Name : PURCHASE_SHIPMENTS Field | Type --------------------------------------------------------------------- ROWKEY | BIGINT (key) PURCHASES_PURCHASEID | BIGINT PURCHASES_PRODUCTID | BIGINT PURCHASES_PRICE | DECIMAL PURCHASES_QUANTITY | INTEGER SHIPMENTS_ID | BIGINT SHIPMENTS_PURCHASEID | BIGINT SHIPMENTS_COURIERID | BIGINT SHIPMENTS_PACKAGEID | BIGINT ---------------------------------------------------------------------
If you want, you can choose to provide a name for the key column:
CREATE STREAM purchase_shipments AS
SELECT
ROWKEY AS purchaseId,
productId,
price,
quantity,
shipments.id as shipmentId,
courierId,
packageId
FROM purchases
FULL OUTER JOIN shipments
WITHIN (0 SECONDS, 1 HOUR)
ON purchases.purchaseId = shipments.purchaseId;
ksql> DESCRIBE purchase_shipments;
Name : PURCHASE_SHIPMENTS
Field | Type
-------------------------------------------------
PURCHASEID | BIGINT (key)
PRODUCTID | BIGINT
PRICE | DECIMAL
QUANTITY | INTEGER
SHIPMENTID | BIGINT
COURIERID | BIGINT
PACKAGEID | BIGINT
-------------------------------------------------
The ksqlDB documentation on synthetic keys covers synthetic key columns in more detail.
Upcoming enhancements to ksqlDB supporting an arbitrary number of key columns will remove the need for synthetic key columns in the near future.
Simple queries
What about the simplest case? A query with no PARTITION BY, GROUP BY, or JOIN? The key column must be in the projection and is copied across to the destination.
CREATE STREAM simple_purchase AS
SELECT
purchaseId, -- the key column,
productId,
quantity
FROM purchases;
The above will copy the purchaseId key column and the two value columns into the simple_purchases stream and underlying Kafka topic. As with other queries, you can add an alias to rename the key column if you want to:
CREATE STREAM simple_purchase AS
SELECT
purchaseId as id,
productId,
quantity
FROM purchases;
Maintaining compatibility with ksqlDB 0.9
You may be wondering what this means for your existing systems if you want to upgrade to 0.10 and need to ensure that the output is compatible with previous versions. In the following section, we’ll explore how you can use the new features to maintain compatibility.
Create statements
The KEY property in the WITH clause is no more. To update to 0.10, explicitly define your key column with the same name as the KEY property, then remove the KEY property and the value column it was referencing:
-- 0.9
CREATE STREAM foo (
ROWKEY INT KEY,
ID INT,
NAME STRING
) WITH (
kafka_topic='s',
value_format='json',
key='ID'
);
-- Compatible 0.10 statement:
CREATE STREAM foo (
ID INT KEY,
NAME STRING
) WITH (
kafka_topic='s',
value_format='json'
);
If you are using value formats that load their column definitions from the Schema Registry, watch out for name clashes between fields defined in the value schema and the name you assign the key column. If you have an ID column in the value schema, you can’t name your key column ID as the name will clash. Pick a different name and make sure you update downstream queries to use this new name in order to avoid unnecessary repartitions:
-- Existing downstream query:
CREATE STREAM bar AS
SELECT COUNT()
FROM foo
GROUP BY ID; -- if this references a value column, ksqlDB will repartition!
Simple queries
Generally, the only thing needed for simple queries is to ensure that the projection includes the key column (which before was implicitly included) and potentially to adjust its name. If the query already has the key column in the projection, then the old query was copying the key into the value. Use the AS_VALUE function to achieve the same output from the updated query:
-- 0.9
CREATE STREAM bar AS
SELECT
ID, -- puts copy of key in value
UCASE(NAME) AS NAME
FROM foo
WHERE e=f;
-- Compatible 0.10 statement (assuming id is the key column):
CREATE STREAM bar AS
SELECT
ID AS ROWKEY, -- key renamed to avoid name clash with value column
AS_VALUE(ID) AS ID, -- copy ID into value
UCASE(NAME) AS NAME
FROM foo;
Repartitioning
You’ll need to ensure the PARTITION BY expression is in the projection. If it already is, then the query was placing a copy of the key column in the value. Use the AS_VALUE function to copy the key into the value:
-- 0.9
CREATE STREAM bar AS
SELECT
ID,
NAME -- copy of key in value
FROM foo
PARTITION BY NAME;
-- Compatible 0.10 statement:
CREATE STREAM bar AS
SELECT
NAME AS ROWKEY -- key renamed to avoid name clash with value column
ID,
AS_VALUE(NAME) AS NAME -- copy NAME into value
FROM foo
PARTITION BY NAME;
Aggregations
Grouping by a single expression requires changes similar to a PARTITION BY: Ensure the projection contains the key column or grouping expression, and use AS_VALUE to copy the key into the value if the projection already included the key column.
-- 0.9
CREATE STREAM bar AS
SELECT
NAME, -- copy of key in value
COUNT() AS COUNT
FROM foo
GROUP BY NAME;
-- Compatible 0.10 statement:
CREATE STREAM bar AS
SELECT
NAME AS ROWKEY -- key renamed to avoid name clash with value column
AS_VALUE(NAME) AS NAME -- copy of NAME in value
COUNT() AS COUNT
FROM foo
GROUP BY NAME;
For multiple expressions, concatenate the key yourself if you need to name it:
-- 0.9
CREATE STREAM bar AS
SELECT
ID, -- copy of key column in value
NAME, -- copy of key column in value
COUNT() AS COUNT
FROM foo
GROUP BY ID, NAME;
-- Compatible 0.10 statement:
CREATE STREAM bar AS
SELECT
CAST(ID AS STRING) + '|+|' + NAME AS ROWKEY -- key in projection
AS_VALUE(ID) AS ID -- copy ID into value
AS_VALUE(NAME) AS NAME -- copy NAME into value
COUNT() AS COUNT
FROM foo
GROUP BY CAST(ID AS STRING) + '|+|' + NAME;
Joins
When joining on columns, you’ll find that the leftmost join column becomes the key column in the result and is no longer in the value by default. Previous versions had the join column both in the key and value. To maintain backward compatibility, use AS_VALUE to copy the key into the value:
-- 0.9:
CREATE STREAM shipped_purchases AS
SELECT
ROWKEY AS purchaseId, -- copy of key in value
productId,
price,
quantity,
shipments.id as shipmentId,
courierId,
packageId
FROM purchases
LEFT JOIN shipments
WITHIN (0 SECONDS, 1 HOUR)
ON purchases.purchaseId = shipments.purchaseId;
-- Compatible 0.10 statement:
CREATE STREAM shipped_purchases AS
SELECT
purchases.purchaseId as ROWKEY, -- key renamed to avoid name clash with value column
AS_VALUE(purchases.purchaseId) AS purchaseId, -- copy purchaseId into value
productId,
price,
quantity,
shipments.id as shipmentId,
courierId,
packageId
FROM purchases
LEFT JOIN shipments
WITHIN (0 SECONDS, 1 HOUR)
ON purchases.purchaseId = shipments.purchaseId;
This may require you to manually expand an existing SELECT *, which would additionally copy the ROWKEY key column from both sides into the value of the result:
-- 0.9:
CREATE STREAM shipped_purchases AS
SELECT *
FROM purchases
LEFT JOIN shipments
WITHIN (0 SECONDS, 1 HOUR)
ON purchases.purchaseId = shipments.purchaseId;
-- Compatible 0.10 statement:
CREATE STREAM shipped_purchases AS
SELECT
purchases.purchaseId as ROWKEY, -- key renamed to avoid name clash with value column
AS_VALUE(purchases.purchaseId) AS purchases_ROWKEY
AS_VALUE(purchases.purchaseId) AS purchaseId, -- copy purchaseId into value
purchases.productId,
purchases.price,
purchases.quantity,
AS_VALUE(shipments.id) AS shipments_ROWKEY
shipments.id,
shipments.courierId,
shipments.packageId
FROM purchases
LEFT JOIN shipments
WITHIN (0 SECONDS, 1 HOUR)
ON purchases.purchaseId = shipments.purchaseId;
Wrapping it up
ksqlDB supports two types of key columns. Anyone familiar with other SQL systems won’t be surprised to see that ksqlDB supports PRIMARY KEY columns on tables. Extending this model, ksqlDB supports not just tables but also streams, and a stream can optionally have a KEY column.
Declaring a column as a key column indicates the data for the column is loaded from or written to the Kafka record’s key, not its value. Having the right key column can avoid costly repartitioning of your data and provides certain guarantees, such as relative ordering of messages. Repartitioning your data can break the ordering guarantees.
ksqlDB 0.10 contains these changes to the SQL language:
- You can finally call your key columns whatever you want
- The confusing WITH(KEY) syntax has been removed (breaking change)
- The Kafka record value no longer needs to contain a copy of the record key (breaking change)
- Streams without key columns are supported
- You must include key columns in your projections (breaking change)
- The key column of many materialized views have changed (breaking change)
While these updates required us to make non-backward-compatible changes to the language, we hope you find that the result is cleaner and more expressive. We have more improvements in the pipeline, so keep an eye on this space.
If you’re ready to check ksqlDB out, head over to ksqldb.io to get started, where you can follow the quick start, read the docs, and learn more.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Introducing Versioned State Store in Kafka Streams
Versioned key-value state stores, introduced to Kafka Streams in 3.5, enhance stateful processing capabilities by allowing users to store multiple record versions per key, rather than only the single latest version per key as is the case for existing key-value stores today...


Delivery Guarantees and the Ethics of Teleportation
This blog post discusses the two generals problems, how it impacts message delivery guarantees, and how those guarantees would affect a futuristic technology such as teleportation.