Introducing Connector Private Networking: Join The Upcoming Webinar!
License Changes for Confluent Platform
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
We’re changing the license for some of the components of Confluent Platform from Apache 2.0 to the Confluent Community License. This new license allows you to freely download, modify, and redistribute the code (very much like Apache 2.0 does), but it does not allow you to provide the software as a SaaS offering (e.g. KSQL-as-a-service).
What this means is that, for example, you can use KSQL however you see fit as an ingredient in your own products or services, whether those products are delivered as software or as SaaS, but you cannot create a KSQL-as-a-service offering. We’ll still be doing all development out in the open and accepting pull requests and feature suggestions. For those who aren’t commercial cloud providers, i.e. 99.9999% of the users of these projects, this adds no meaningful restriction on what they can do with the software, while allowing us to continue investing heavily in its creation.
This has no effect on Apache Kafka, which is developed as part of the Apache Software Foundation and remains under the Apache 2.0 license, and to which we continue to contribute actively. It just impacts the open source components that Confluent maintains.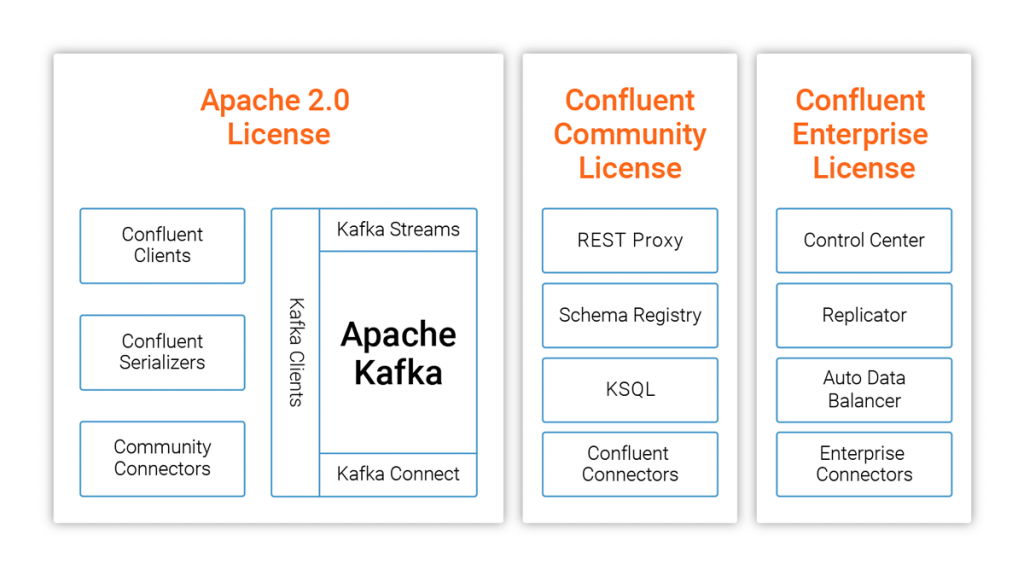
Why Do This?
We think it is a necessary step. This lets us continue to invest heavily in code that we distribute for free, while sustaining a healthy business that funds this investment. I’ll explain why both of these things are important.
First, is this kind of investment necessary at all? For many simple open source projects, I don’t think it is. There are thousands of libraries thriving on GitHub that don’t need much investment beyond a few volunteer contributors. Distributed data systems are different. Building a successful new distributed data platform is just excruciatingly hard.
You don’t need to take my word for it, though, it turns out this experiment has been done. Dozens of NoSQL databases emerged in the 2009-2010 timeframe. Some were created as part-time projects, some came out of the internal infrastructure of large web companies, and some were created as commercial ventures. What I think is most stark is that the only systems that remained relevant through to today are those that, whatever their origin, managed to develop a stable commercial entity that helped sustain ongoing investment. Those that did this (MongoDB, ElasticSearch, Cassandra, Hadoop) all continue to thrive and have become part of the modern stack. Those that didn’t (Voldemort, Dynomite, CouchDB, and a dozen others) have all fallen by the wayside, despite early popularity. They still exist, but most likely you have never heard of them.
The reason for this difference seems stark to me, having worked in open source both within companies like LinkedIn, as a volunteer, and as part of Confluent. When we were originally developing Kafka at LinkedIn, the team was just a few people in total for most of my time there. I wrote the original code base on my Christmas vacation because the project had no official resourcing. That small Kafka team wrote the code, ran the service, as well as tended to the open source community and eventually helped convince LinkedIn to move the project into Apache. This would mean coding during the day, then attending to issues and bugs reported to the community, or doing a meetup in the evening, and waking up at night to deal with the occasional operational issue. But as the community grew, the needs grew even faster: code review of outside patches often lagged, and clients outside Java mostly didn’t work.
The formation of Confluent has allowed us to invest much more than LinkedIn ever could. Many of the people who were eking out small contributions late at night on a pure passion basis could now get paid to contribute full time. Confluent could fund not just code contributions but also the sizable cloud bill to run the kind of large scale distributed torture tests that are needed to keep a code base stable while scaling contribution from a growing community. The code is still not perfect, but the rate at which it’s improving is vastly greater.
In other words I do believe business can help fund a virtuous cycle of open source contribution.
In a world in which data systems are delivered as on-premises software, we as an industry have figured out how to build sustainable companies that can drive this kind of virtuous cycle. It isn’t easy, but starting a company never is. In that model, we’ve found that permissive open source licensing such as Apache 2.0 can be the major component of a thriving software offering that sustains a healthy business. However, the world has significantly changed with the rise of cloud offerings that provide this kind of software as a service. In this new world, the cloud providers have significant advantages: they control the pricing of all resources a service provider will use and can tightly integrate their own services across all their offerings.
The major cloud providers (Amazon, Microsoft, Alibaba, and Google) all differ in how they approach open source. Some of these companies partner with the open source companies that offer hosted versions of their system as a service. Others take the open source code, bake it into the cloud offering, and put all their own investments into differentiated proprietary offerings. The point is not to moralize about this behavior, these companies are simply following their commercial interests and acting within the bounds of what the license of the software allows.
As a company, one solution we could pursue would be for us to build more proprietary software and pull back from our open source investments. But we think the right way to build fundamental infrastructure layers is with open code. As workloads move to the cloud we need a mechanism for preserving that freedom while also enabling a cycle of investment, and this is our motivation for the licensing change.
We think this is a positive change and one that can help ensure small open source communities aren’t acting as free and unsustainable R&D for tech giants that put sustaining resources only into their own differentiated proprietary offerings.
What Does This Mean?
I think the new license is simple enough to read, even for a non-lawyer, and both in the license and in this announcement we’ve tried to be as up-front as possible about what we’re trying to allow, what we’re trying to prevent, and why.
There are two cynical interpretations that I worry about with this announcement. The first is that this indicates that Confluent is struggling and needs to do this to make money. This is not the case, Confluent is doing exceedingly well, and we think that is a fantastic thing, both for our customers, and for our ability to invest in the community and open source. Our goal with this change is to ensure that we are able to sustain that growth, and continue to invest in open and free offerings.
The second cynical interpretation is, ironically, the opposite: that this is part of a greedy ploy to extract ever more money by a rapacious corporation. Against that I can say only this: Confluent was not created as just a way to make money. We have a vision for the architecture of a modern data-driven company that is centered around streams of events. We want to make that a reality in the world. Confluent is a group of people that believe in this idea, and for many of us, our work on this project predates Confluent itself. That early work in building code and community wasn’t part of a decade long plot to commercialize it. Rather, we think this plan to re-architect all the companies in the world around event streams is a bold one and will take a lot of work. This change puts us in a position to continue that work for the decades ahead and contribute to the software, community, and practices that make it a reality.
All this doesn’t mean we aren’t a commercial entity or focused on the business we’re building. If we’re successful, the streaming platform will sit at the very center of a company’s architecture and will be as important, valuable and strategic a data platform as relational databases have been. We think this represents a massive paradigm shift and will be the basis of a fantastic business.
A Few Questions Answered
Here are the answers to a few other questions you may have:
How does this impact Apache Kafka?
It doesn’t. We continue to contribute to Apache Kafka via the ASF under the Apache 2.0 license.
Can I download, modify, or redistribute the code?
Yes. The code is all still right there on GitHub.
Can I embed the code in software I distribute?
Yes.
Can I use the code to build a SaaS product?
Yes, in almost all cases. If you are building a SaaS product you may use the Confluent community software. The only restriction is on managed service offerings that offer the software as a competing offering with our own managed service offering of the software. So for example, you cannot build a SaaS offering where KSQL itself is the product being offered.
For additional questions, please see our detailed FAQ.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...