[Webinar] Harnessing the Power of Data Streaming Platforms | Register Now
Conquering Hybrid Cloud with Replicated Event-Driven Architectures
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Potential advantages of hybrid cloud architectures include avoiding vendor lock-in, increasing system resilience, optimizing costs, and inducing price competition among cloud providers.
Hybrid cloud architectures require the ability to securely and effortlessly move data from environment to environment. As the number of environments, applications, and services grow, spanning on prem and cloud, this challenge can become exponentially harder. However, event-driven architectures on Apache Kafka® can address these challenges, and in this post, we’ll see how by looking at an example using Apache Kafka, Google Cloud Platform (GCP), and Confluent Cloud.
Kafka unlocks hybrid architectures
While discussions about event-driven architectures often center on benefits for application engineering, there are also operational benefits for organizations. When engineering groups adopt an event-first mindset, the organization may reap significant benefits controlling operational complexity and cost in a hybrid cloud environment. Kafka’s durability, scalability, high throughput, and fault tolerance make it uniquely positioned to thrive as the bridge between cloud and on-prem environments.
Engineering groups are often faced with a complex web of network-connected services that must be secured, monitored, and audited. As organizations embrace hybrid architectures, this complexity grows as these services bridge different infrastructure environments and public networks. This interconnected mesh presents significant challenges related to security, complexity, and costs.
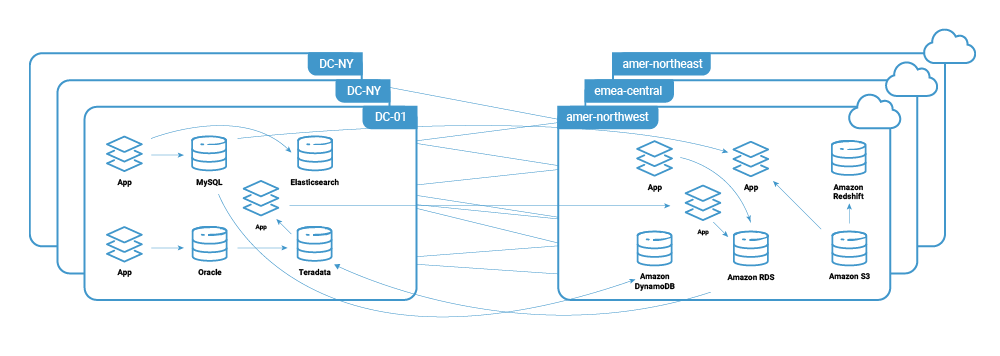
In addition to the security and complexity concerns, cloud vendors charge for internet and cross-region network traffic but do not charge for intra-regional bandwidth. As you expand your hybrid cloud footprint in this way, network costs may begin to overwhelm the cost of compute and storage resources.
Introducing Kafka and Confluent Replicator to create a replicated central event nervous system across a hybrid cloud deployment provides substantial benefits.
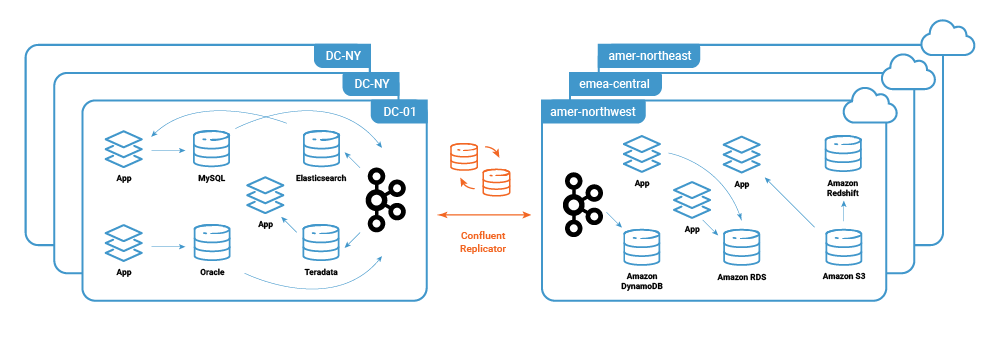
Replicator provides mature, robust, and advanced Kafka replication. Features like topic auto-creation, schema replication, partition detection, and reliable active-active replication make replicated event-driven architectures reachable for even small teams.
Combined with Replicator, Kafka allows operators to secure and monitor only a few public communication channels between hybrid cloud environments, greatly reducing security and complexity risks. At the software level, there are often many consuming applications to a few producers, and most software architectures will follow a write-once, read-many-times pattern. Utilizing Kafka, and replicating a single durable event stream across your environments allows consuming applications to live in the most desirable environment, making them free to read as many times as necessary.
Running Kafka clusters is progressively getting easier. Current deployment platforms include native JVM deployments, Docker, Kubernetes (K8s), and serverless. For more information on running Kafka in a managed Kubernetes environment, see the Confluent Platform on Google Kubernetes Engine (GKE) demo and check out the Bridge to Cloud white paper for more information.
Fintech use case: Electronic stock trading
To see how a business might benefit from a hybrid deployment, let’s look at a hypothetical architecture. For this blog post, we’ll focus on an electronic stock trading system with multiple components that are both generating and consuming events. The business wants to optimize costs while maintaining security, functionality, and service-level agreements between the components. The business is also interested in leveraging modern service offerings available in cloud providers.
Often electronic trading systems are positioned near the exchanges to which they transact. Proximity to the exchanges reduces message latency for faster order execution as well as increased resiliency as they are often connected by redundant and direct connections. As a result of this market dynamic, space within these datacenters is competitive and comes at a premium.
In a single datacenter deployment, the Tier 2 components operate inside the same competitively priced datacenter as the Tier 1 systems. This forces organizations to expend the same resources supporting Tier 2 components as that for Tier 1 systems. By migrating Tier 2 systems to environments that are less expensive or provide advanced services, organizations have the opportunity to significantly optimize costs.
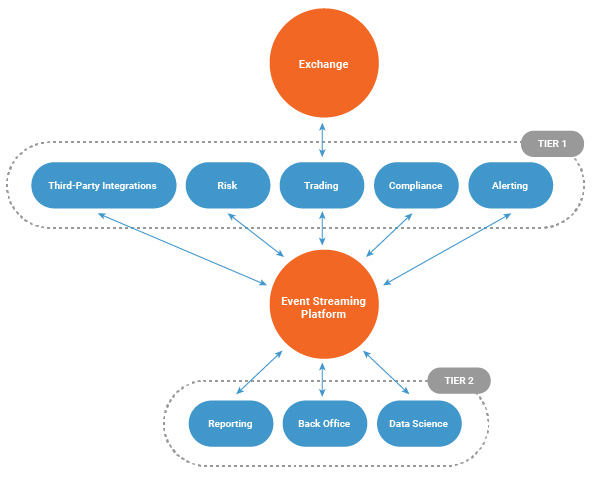
The first step in migrating to a hybrid cloud deployment would be to replicate the event streaming platform to a destination cluster. Introducing Confluent Replicator to the architecture allows the migration to be phased, as data can be replicated and verified prior to migrating consuming applications.
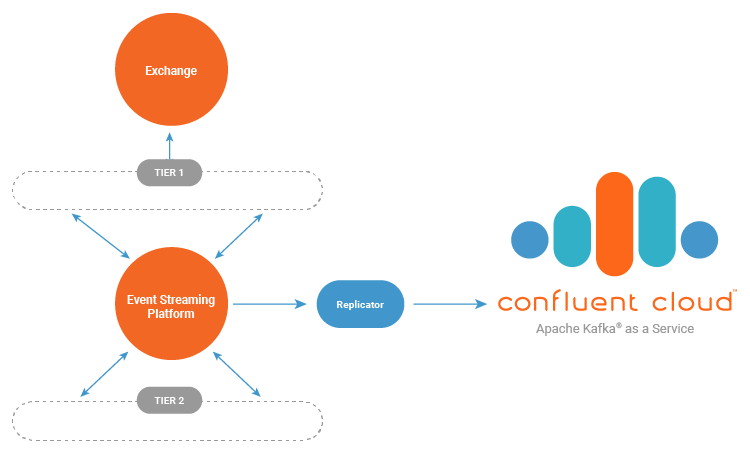
The event streaming platform is replicated into Confluent Cloud, which allows the organization to take advantage of a fully managed Apache Kafka service as its durable backbone. Once the event streaming platform is properly replicating, we can migrate the Tier 2 components to a connected computing platform that offers flexible and lower-cost resource options.
The consumption-based pricing model of Confluent Cloud optimizes resources during business downtimes like normal market closures. Confluent Cloud provides a strong data retention policy through its service-level agreement (SLA) on top of a required three broker replication policy. As a result, the retention policies in the co-located Kafka can be minimized in order to reduce storage resource requirements. Replicator produces data into Confluent Cloud with full replication enabled (acks=all) to strengthen the data durability profile. For more information on Confluent Cloud, see the documentation on plans and migrating between them.
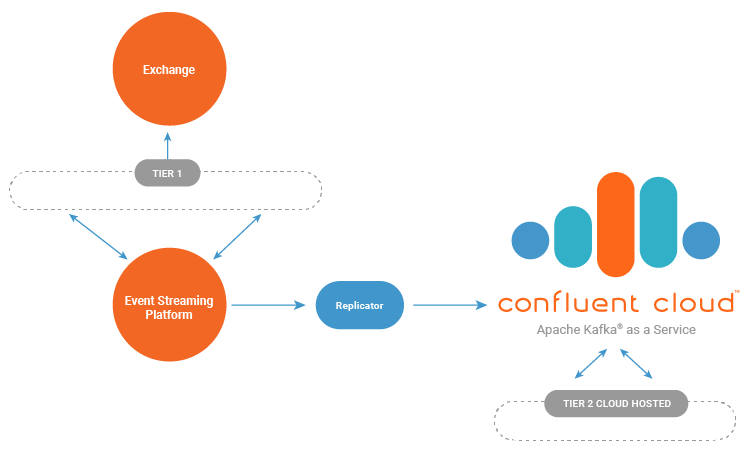
In this final hybrid state, our hypothetical system reserves the premium co-located resources for only the critical Tier 1 systems which benefit from the reduced latency to and from exchanges and each other. This architecture allows the system to push Tier 2 components out away from the expensive co-located datacenter and into a cloud provider. Cloud services provide cost-saving mechanisms like reserved instances, serverless databases, and computing systems, allowing the organization to further optimize costs.
Hybrid cloud demo
Confluent provides an examples GitHub repository that contains a wealth of resources for engineers looking to get started with Apache Kafka and Confluent Platform. We are going to look at the Google Kubernetes Engine to Confluent Cloud with Confluent Replicator demo as an example of getting started with replicated event streams in a hybrid cloud deployment.
This demo is built with Kubernetes and leverages Confluent Operator, which makes running stateful services such as Kafka on Kubernetes easier. If you’re already running stateless workloads on Kubernetes, you may optimize operations by also running Kafka on Kubernetes with Operator. The architectural ideas discussed in this post are also applicable to non-Kubernetes environments, so if you’re not ready for Kubernetes, see the hybrid on-prem Kafka to Confluent Cloud demo for an example that uses a local Kafka deployment in place of a Kubernetes-based cluster.
| Note: this demo is not meant to be a production deployment solution. Instead, it should be used as a learning tool for Kafka, Kubernetes, Operator, Replicator, and Confluent Cloud. |
The following diagram illustrates what the demonstration will deploy for you:
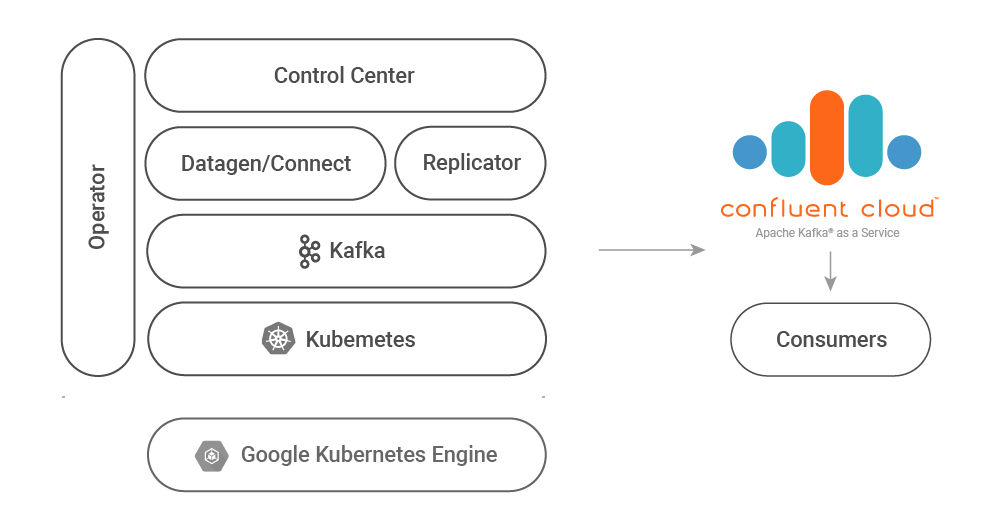
The demo can utilize an existing GKE cluster or provision one for you. See the Running the Demo section of the documentation for details and customization options.
Using Helm Charts, Kubectl, and Confluent Operator, the demo deploys Confluent Platform into a GKE cluster and includes a mock data generator that produces simulated stock trade data. We can use the mock data to experiment with the setup and explore the various services.
Running the demo is as easy as setting up GKE and Confluent Cloud accounts, cloning the source repository locally, and executing a single command:
$ make demo
As the demo proceeds with the service deployments, it will print out the commands as it executes them for your evaluation. Here you can see Helm, kubectl, and Operator working together to properly deploy Kafka Connect:
The Kubernetes ecosystem is full of helpful tools for observing your Kubernetes deployments. Try using the K9s tool to live monitor the Pods as Confluent Operator deploys them:
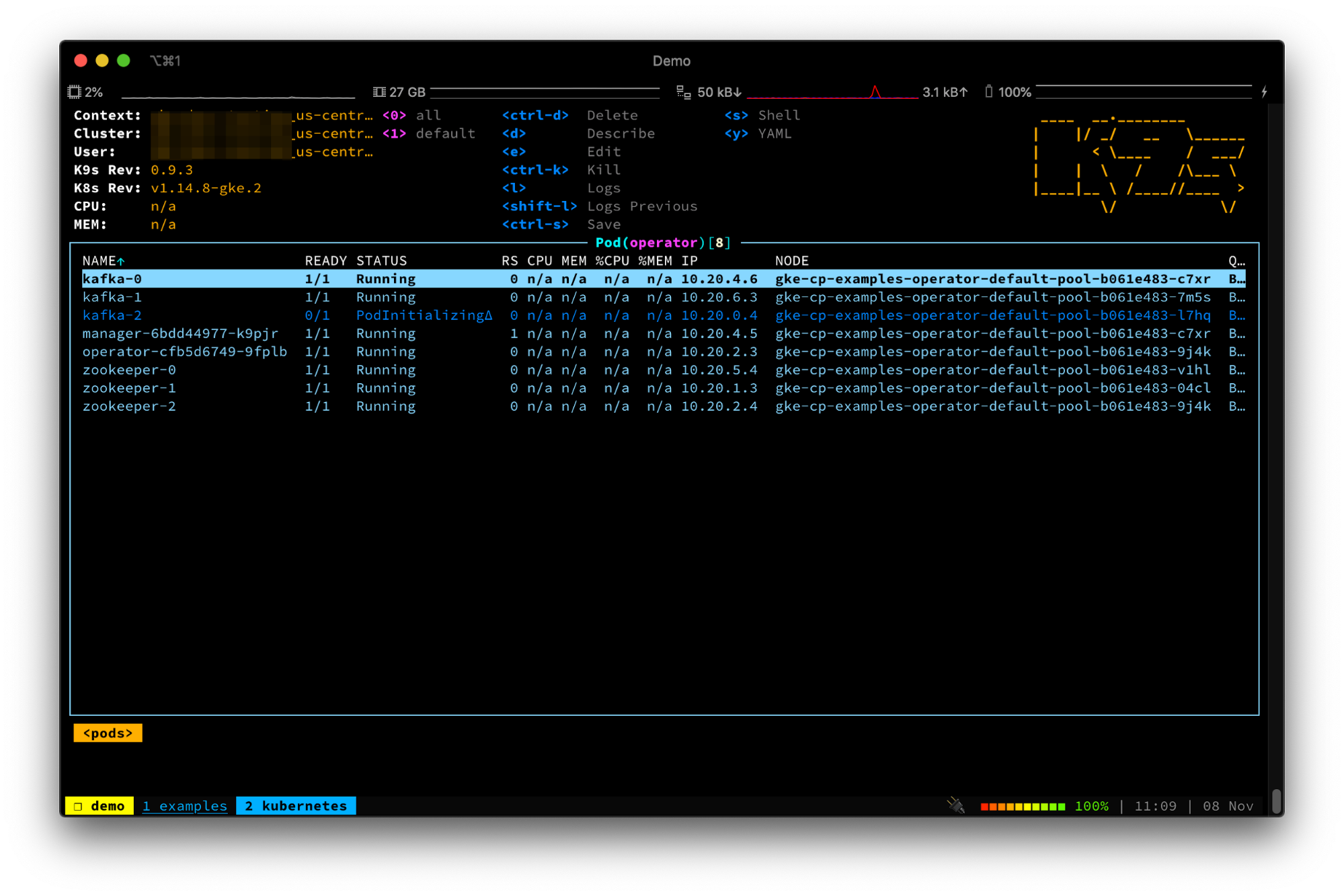
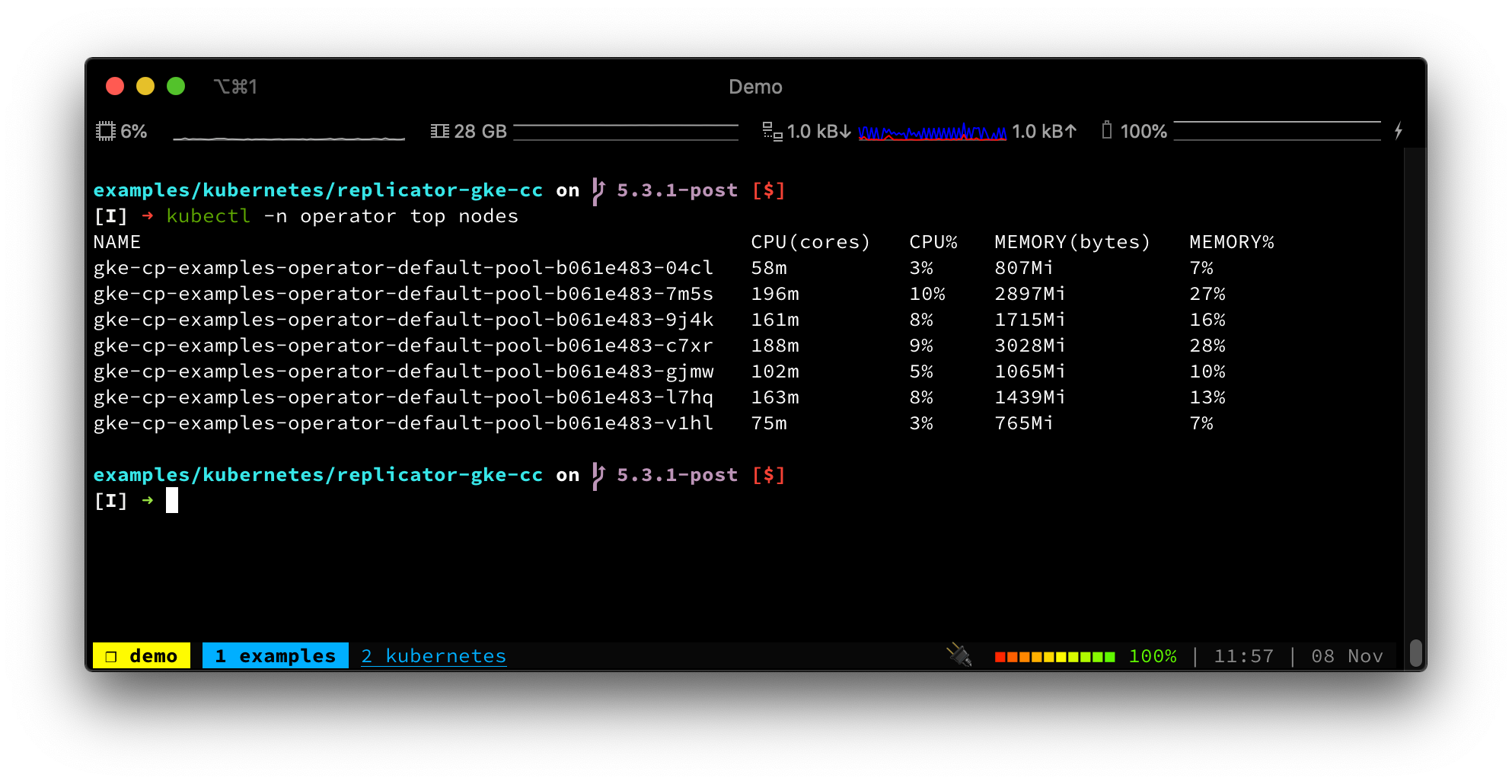
Or, use kubectl to view your node pool resources:
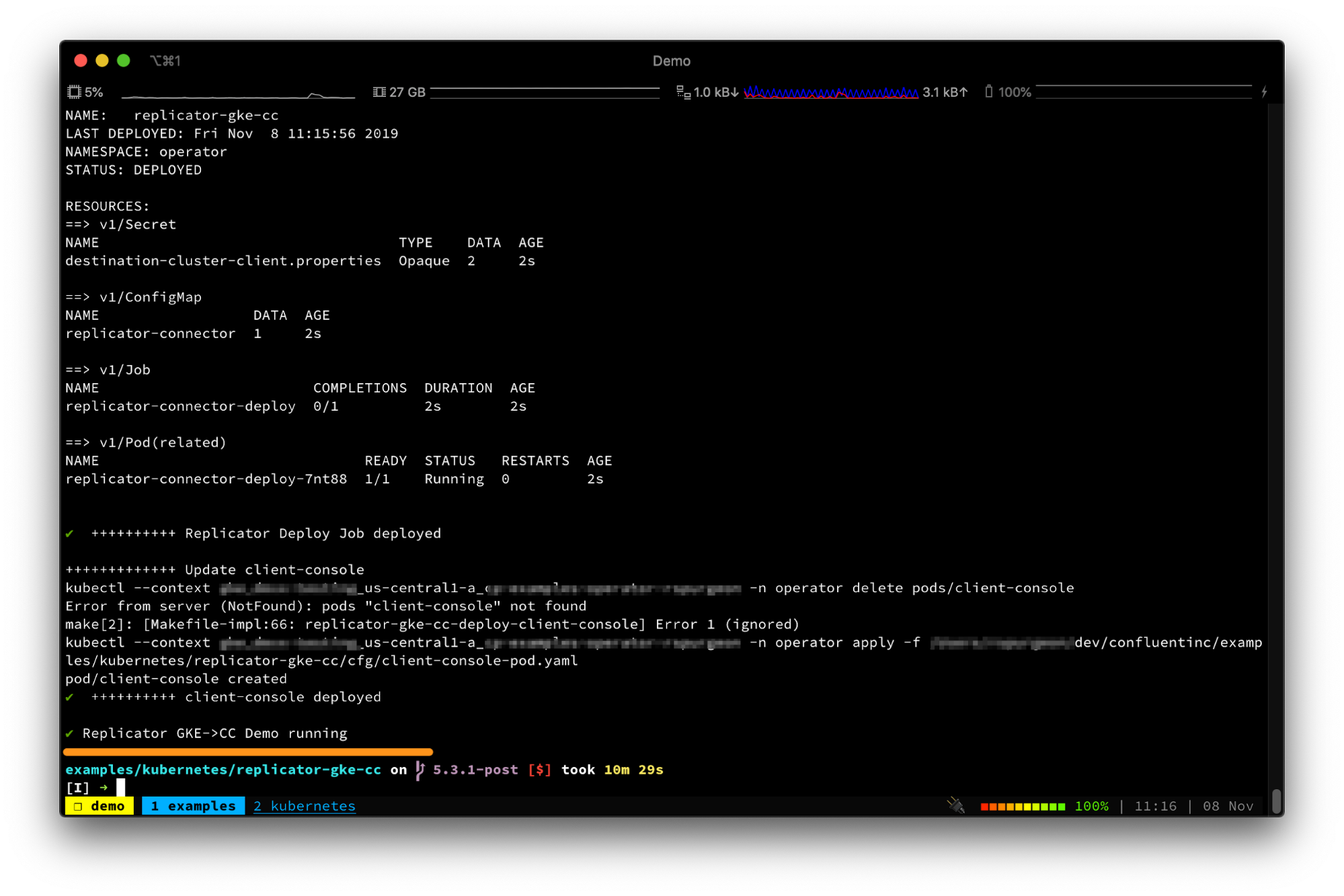
In less than 10 minutes, you have a mutli-cloud environment between GKE and Confluent Cloud with a replicated topic. The demo reports success with ✔ Replicator GKE->CC Demo running:
Confluent Cloud provides fully managed ksqlDB to allow a user to run stream processing applications on data in Confluent Cloud. To try it out, create a ksqlDB application in your Confluent Cloud account:
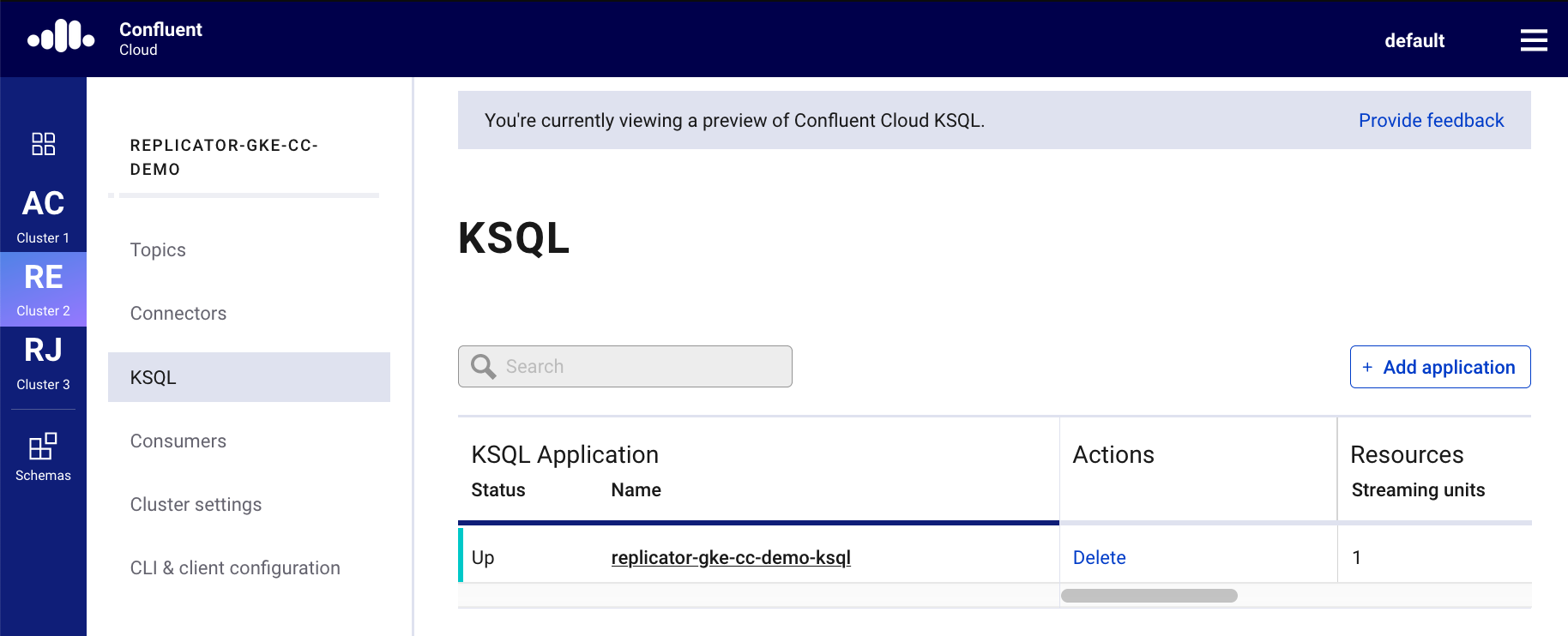
Experiment with the ksqlDB syntax to build stream processing applications directly in the ksqlDB editor.
For example, create a ksqlDB stream from the stock-trades topic. This topic has been replicated from the GKE cluster into your Confluent Cloud account by Replicator, which was deployed earlier in the demo.
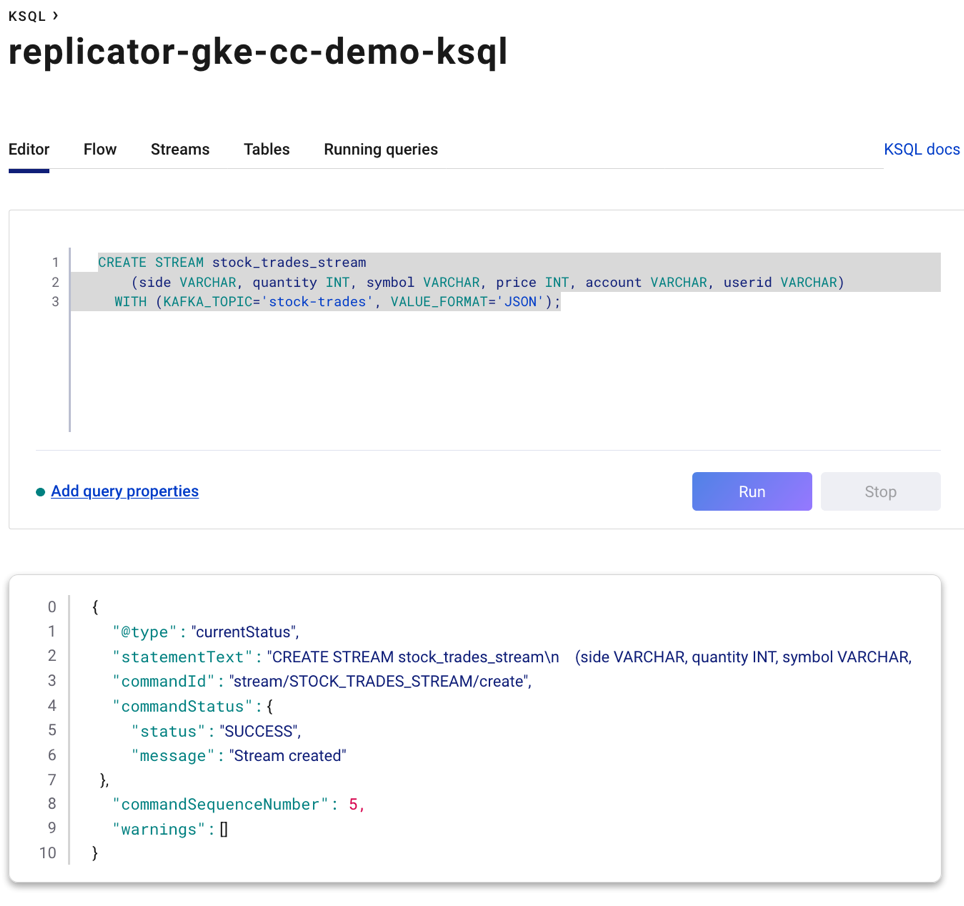
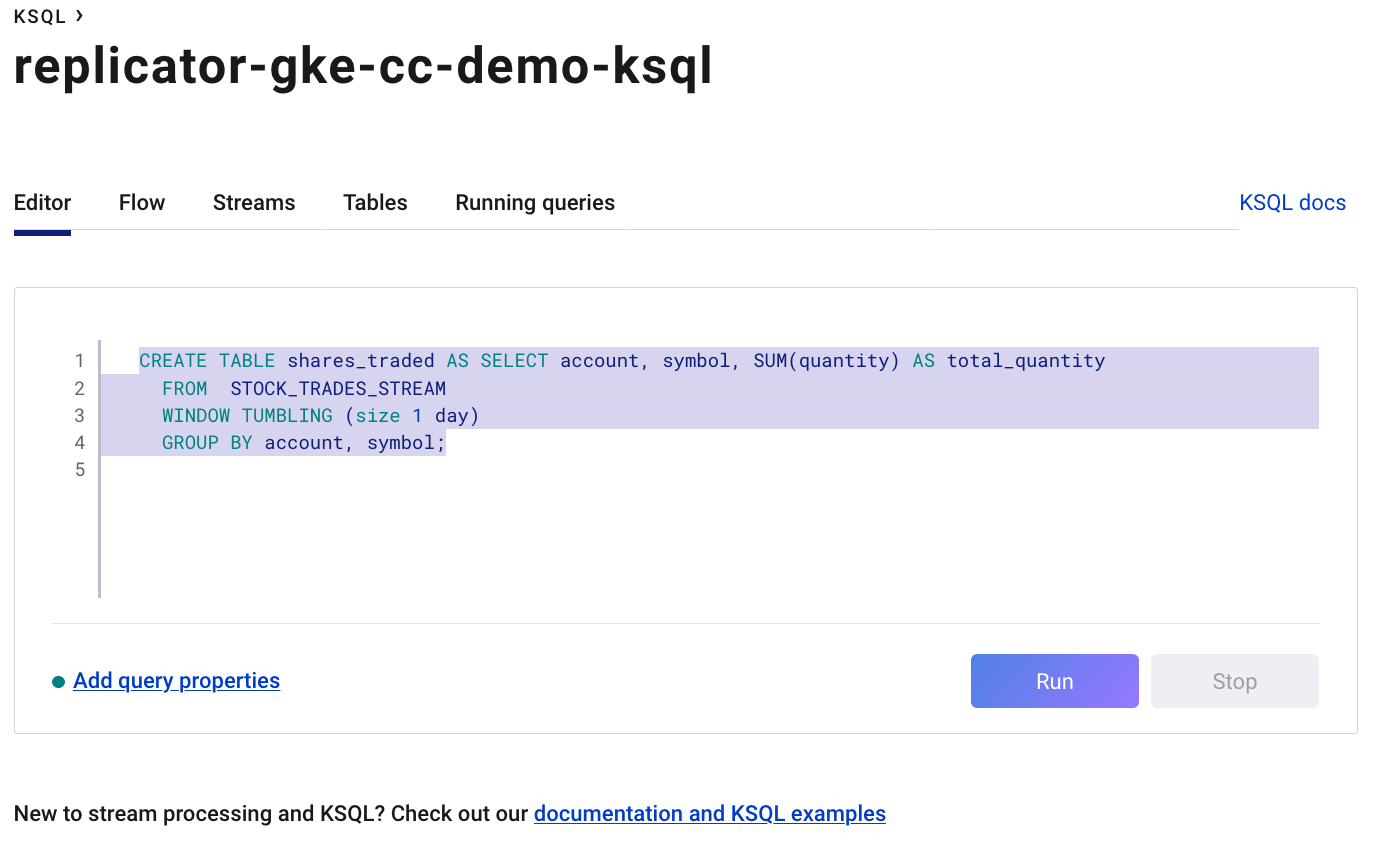
From the stream, create a ksqlDB table using a tumbling window and aggregate the trade quantities using the ksqlDB SUM function.
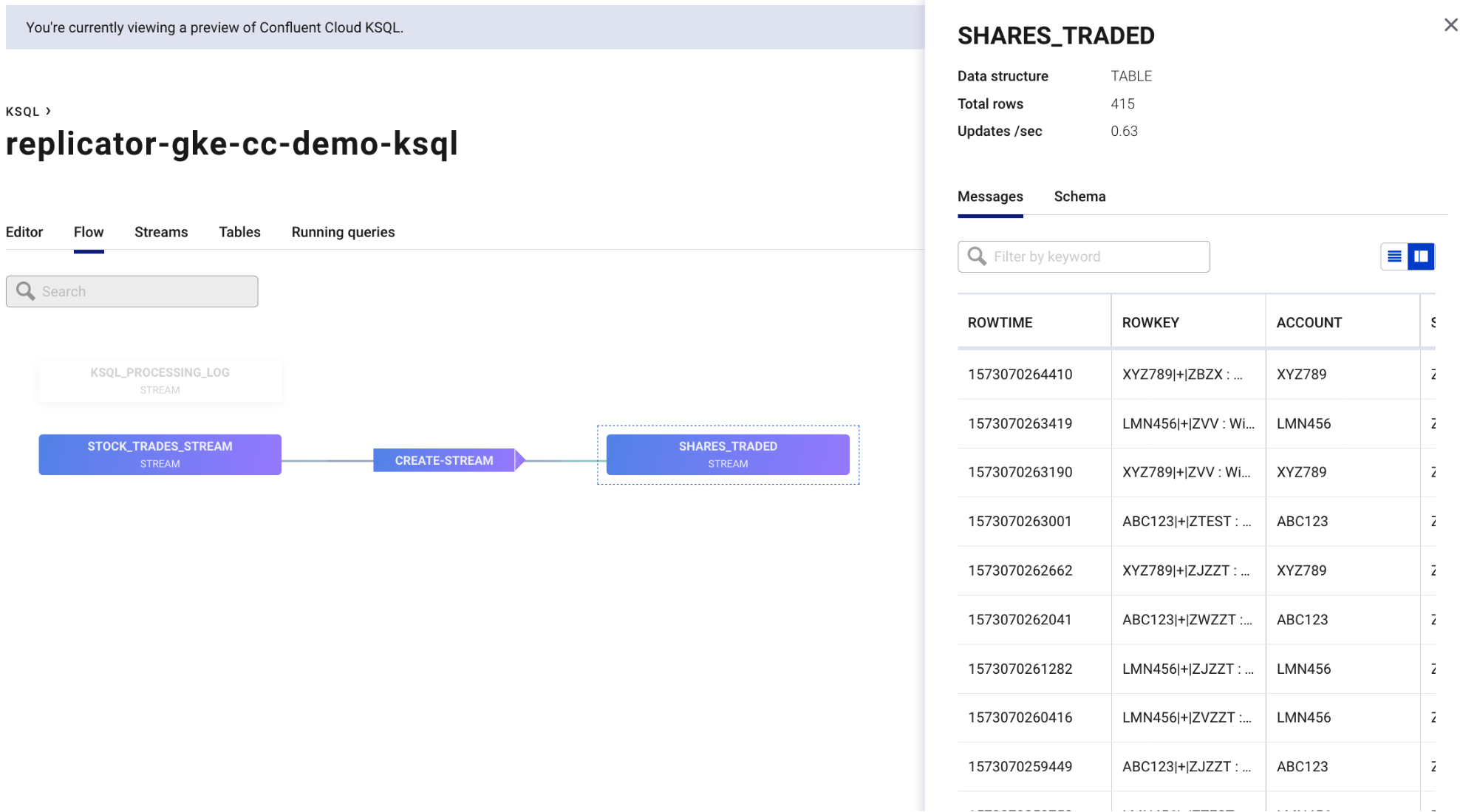
Examine the event streaming application by viewing the ksqlDB Flow feature. In the diagram, you can click on the components to view details.
Summary
Replicated event-driven architectures can be an effective ally for your operations team. Hybrid cloud solutions provide opportunities to optimize costs, mitigate risks, and enable powerful new features.
To get started, check out the demo repository and documentation for specifics on running the example yourself.
For more, be sure to check out Confluent Cloud, a fully managed event streaming service based on Apache Kafka. Use the promo code CL60BLOG to get an additional $60 of free Confluent Cloud usage.*
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...