[Webinar] Harnessing the Power of Data Streaming Platforms | Register Now
Spring for Apache Kafka Deep Dive – Part 1: Error Handling, Message Conversion and Transaction Support
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Following on from How to Work with Apache Kafka in Your Spring Boot Application, which shows how to get started with Spring Boot and Apache Kafka®, here we’ll dig a little deeper into some of the additional features that the Spring for Apache Kafka project provides.
Spring for Apache Kafka brings the familiar Spring programming model to Kafka. It provides the KafkaTemplate for publishing records and a listener container for asynchronous execution of POJO listeners. Spring Boot auto-configuration wires up much of the infrastructure so that you can concentrate on your business logic.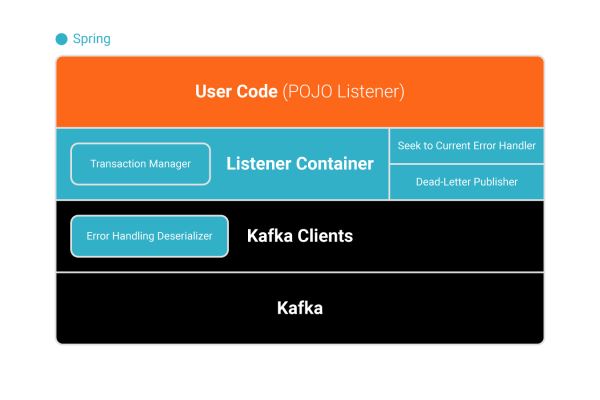
Error recovery
Consider this simple POJO listener method:
@KafkaListener(id = "fooGroup", topics = "topic1")
public void listen(String in) {
logger.info("Received: " + in);
if (in.startsWith("foo")) {
throw new RuntimeException("failed");
}
}
By default, records that fail are simply logged and we move on to the next one. We can, however, configure an error handler in the listener container to perform some other action. To do so, we override Spring Boot’s auto-configured container factory with our own:
@Bean
public ConcurrentKafkaListenerContainerFactory kafkaListenerContainerFactory(
ConcurrentKafkaListenerContainerFactoryConfigurer configurer,
ConsumerFactory<Object, Object> kafkaConsumerFactory) {
ConcurrentKafkaListenerContainerFactory<Object, Object> factory = new ConcurrentKafkaListenerContainerFactory<>();
configurer.configure(factory, kafkaConsumerFactory);
factory.setErrorHandler(new SeekToCurrentErrorHandler()); // <<<<<<
return factory;
}
Note that we can still leverage much of the auto-configuration, too.
The SeekToCurrentErrorHandler discards remaining records from the poll() and performs seek operations on the consumer to reset the offsets so that the discarded records are fetched again on the next poll. By default, the error handler tracks the failed record, gives up after 10 delivery attempts and logs the failed record. However, we can also send the failed message to another topic. We call this a dead letter topic.
The following example puts it all together:
@Bean
public ConcurrentKafkaListenerContainerFactory kafkaListenerContainerFactory(
ConcurrentKafkaListenerContainerFactoryConfigurer configurer,
ConsumerFactory<Object, Object> kafkaConsumerFactory,
KafkaTemplate<Object, Object> template) {
ConcurrentKafkaListenerContainerFactory<Object, Object> factory = new ConcurrentKafkaListenerContainerFactory<>();
configurer.configure(factory, kafkaConsumerFactory);
factory.setErrorHandler(new SeekToCurrentErrorHandler(
new DeadLetterPublishingRecoverer(template), 3));
return factory;
}
@KafkaListener(id = "fooGroup", topics = "topic1") public void listen(String in) { logger.info("Received: " + in); if (in.startsWith("foo")) { throw new RuntimeException("failed"); } }
@KafkaListener(id = "dltGroup", topics = "topic1.DLT") public void dltListen(String in) { logger.info("Received from DLT: " + in); }
Deserialization errors
But what about deserialization exceptions, which occur before Spring gets the record? Enter the ErrorHandlingDeserializer. This deserializer wraps a delegate deserializer and catches any exceptions. These are then forwarded to the listener container, which sends them directly to the error handler. The exception contains the source data so you can diagnose the problem.
Domain objects and inferring the type
Consider the following example:
@Bean
public RecordMessageConverter converter() {
return new StringJsonMessageConverter();
}
@KafkaListener(id = "fooGroup", topics = "topic1")
public void listen(Foo2 foo) {
logger.info("Received: " + foo);
if (foo.getFoo().startsWith("fail")) {
throw new RuntimeException("failed");
}
}
@KafkaListener(id = "dltGroup", topics = "topic1.DLT")
public void dltListen(Foo2 in) {
logger.info("Received from DLT: " + in);
}
Notice we are now consuming objects of type Foo2. The message converter bean infers the type to convert to the parameter type in the method signature.
The converter automatically “trusts” the type. Spring Boot auto-configures the converter into the listener container.
On the producer side, the sent object can be a different class (as long as it is type compatible):
@RestController
public class Controller {
@Autowired
private KafkaTemplate<Object, Object> template;
@PostMapping(path = "/send/foo/{what}")
public void sendFoo(@PathVariable String what) {
this.template.send("topic1", new Foo1(what));
}
}
And:
spring:
kafka:
producer:
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
$ curl -X POST http://localhost:8080/send/foo/fail
Here, we use a StringDeserializer and the “smart” message converter on the consumer side.
Multi-method listeners
We can also use a single listener container and route to specific methods based on the type. We can’t infer the type this time since the type is used to select the method to call.
Instead, we rely on type information passed in the record headers to map from the source type to the target type. Also, since we do not infer the type, we need to configure the message converter to “trust” the package for the mapped type.
In this case, we’ll use a message converter on both sides (together with a StringSerializer and a StringDeserializer). The following example of the consumer-side converter puts it all together:
@Bean
public RecordMessageConverter converter() {
StringJsonMessageConverter converter = new StringJsonMessageConverter();
DefaultJackson2JavaTypeMapper typeMapper = new DefaultJackson2JavaTypeMapper();
typeMapper.setTypePrecedence(TypePrecedence.TYPE_ID);
typeMapper.addTrustedPackages("com.common");
Map<String, Class<?>> mappings = new HashMap<>();
mappings.put("foo", Foo2.class);
mappings.put("bar", Bar2.class);
typeMapper.setIdClassMapping(mappings);
converter.setTypeMapper(typeMapper);
return converter;
}
Here, we map from “foo” to class Foo2 and “bar” to class Bar2. Notice that we have to tell it to use the TYPE_ID header to determine the type for the conversion. Again, Spring Boot auto-configures the message converter into the container. Below is the producer-side type mapping in a snippet of the application.yml file; the format is a comma-delimited list of token:FQCN:
spring:
kafka:
producer:
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
properties:
spring.json.type.mapping: foo:com.common.Foo1,bar:com.common.Bar1
This configuration maps class Foo1 to “foo” and class Bar1 to “bar.”
Listener:
@Component
@KafkaListener(id = "multiGroup", topics = { "foos", "bars" })
public class MultiMethods {
@KafkaHandler
public void foo(Foo1 foo) {
System.out.println("Received: " + foo);
}
@KafkaHandler
public void bar(Bar bar) {
System.out.println("Received: " + bar);
}
@KafkaHandler(isDefault = true)
public void unknown(Object object) {
System.out.println("Received unknown: " + object);
}
}
Producer:
@RestController
public class Controller {
@Autowired
private KafkaTemplate<Object, Object> template;
@PostMapping(path = "/send/foo/{what}")
public void sendFoo(@PathVariable String what) {
this.template.send(new GenericMessage<>(new Foo1(what),
Collections.singletonMap(KafkaHeaders.TOPIC, "foos")));
}
@PostMapping(path = "/send/bar/{what}")
public void sendBar(@PathVariable String what) {
this.template.send(new GenericMessage<>(new Bar(what),
Collections.singletonMap(KafkaHeaders.TOPIC, "bars")));
}
@PostMapping(path = "/send/unknown/{what}")
public void sendUnknown(@PathVariable String what) {
this.template.send(new GenericMessage<>(what,
Collections.singletonMap(KafkaHeaders.TOPIC, "bars")));
}
}
Transactions
Transactions are enabled by setting the transactional-id-prefix in the application.yml file:
spring:
kafka:
producer:
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
transaction-id-prefix: tx.
consumer:
properties:
isolation.level: read_committed
When using spring-kafka 1.3.x or later and a kafka-clients version that supports transactions (0.11 or later), any KafkaTemplate operations performed in a @KafkaListener method will participate in the transaction, and the listener container will send the offsets to the transaction before committing it. Recognize that we also set the isolation level for the consumers to not have visibility into uncommitted records. The following example pauses the listener so that we can see the effect of this:
@KafkaListener(id = "fooGroup2", topics = "topic2")
public void listen(List foos) throws IOException {
logger.info("Received: " + foos);
foos.forEach(f -> kafkaTemplate.send("topic3", f.getFoo().toUpperCase()));
logger.info("Messages sent, hit enter to commit tx");
System.in.read();
}
@KafkaListener(id = "fooGroup3", topics = "topic3")
public void listen(String in) {
logger.info("Received: " + in);
}
The producer for this example sends multiple records in a single transaction:
@PostMapping(path = "/send/foos/{what}")
public void sendFoo(@PathVariable String what) {
this.template.executeInTransaction(kafkaTemplate -> {
StringUtils.commaDelimitedListToSet(what).stream()
.map(s -> new Foo1(s))
.forEach(foo -> kafkaTemplate.send("topic2", foo));
return null;
});
}
curl -X POST http://localhost:8080/send/foos/a,b,c,d,e
Received: [Foo2 [foo=a], Foo2 [foo=b], Foo2 [foo=c], Foo2 [foo=d], Foo2 [foo=e]]
Messages sent, hit Enter to commit tx
Received: [A, B, C, D, E]
Conclusion
Using Spring with Apache Kafka can eliminate much of the boilerplate code that you otherwise need. It also adds features such as error handling, retrying, and record filtering—and we’ve only just touched the surface.
Learn more
To learn more about using Spring Boot with Apache Kafka, take this free course with expert videos and guides.
You can also sign up for Confluent Cloud and use the promo code SPRING200 for an additional $200 of free Confluent Cloud usage.*
Further reading
- Spring for Apache Kafka Deep Dive – Part 2: Apache Kafka and Spring Cloud Stream
- Spring for Apache Kafka Deep Dive – Part 3: Apache Kafka and Spring Cloud Data Flow
- Spring for Apache Kafka Deep Dive – Part 4: Continuous Delivery of Event Streaming Pipelines
- How to Work with Apache Kafka in Your Spring Boot Application
- Code samples for Spring Boot and Apache Kafka
- Spring for Apache Kafka documentation
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Kafka-docker-composer: A Simple Tool to Create a docker-compose.yml File for Failover Testing
The Kafka-Docker-composer is a simple tool to create a docker-compose.yml file for failover testing, to understand cluster settings like Kraft, and for the development of applications and connectors.


How to Process GitHub Data with Kafka Streams
Learn how to track events in a large codebase, GitHub in this example, using Apache Kafka and Kafka Streams.