[Webinar] Harnessing the Power of Data Streaming Platforms | Register Now
Spring Your Microservices into Production with Kubernetes and GitOps
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Microservice architectures continue to grow within engineering organizations as teams strive to increase development velocity. Microservices promote the idea of modularity as a first-class citizen in a distributed architecture, enabling parallel development and components with independent release cycles. As with all technology decisions, there are trade-offs to consider. With microservices, these include the potential to lose centralized development standards as well as increased operational complexity.
Fortunately, there are strategies for managing these challenges. First, we will look at a refactored Kafka Streams based service using a Microservices Framework that provides standards for testing, configuration, and integrations. We then use the existing streaming-ops project to build, validate, and promote the new service from development to production environments. Although not required, if you wish to perform the steps detailed in this post, you will need your own version of the streaming-ops project as detailed in the documentation.
Microservice architecture challenges
As engineering groups adopt microservices architectures, individual teams may start to fragment in their technical decisions. This can lead to a variety of challenges:
- Multiple solutions to common needs across the larger organization will violate the “Don’t Repeat Yourself” principle
- Developers looking to change teams or cross collaborate are faced with learning multiple technology stacks and architectural decisions
- Operational teams that validate and deploy multiple applications face complications as they have to accommodate each team’s technology decisions
Spring Boot
To alleviate these risks, developers are turning to Microservice Frameworks to standardize common development tasks, and Spring Boot (an extension to the Spring  framework) is a popular example of one of these frameworks.
framework) is a popular example of one of these frameworks.
Spring Boot provides opinionated solutions to common software development concerns, for example, configuration, dependency management, testing, web services, and other external system integrations like Apache Kafka®. Let’s look at an example of utilizing Spring Boot to rewrite an existing Kafka Streams based microservice.
The orders-service
The streaming-ops project is a production-like environment running microservices based on existing Kafka Streams examples. We have refactored one of these services to utilize Spring Boot and the full project source code can be found in the GitHub repository. Let’s look at some of the highlights.
Kafka integration
The Spring for Apache Kafka library provides Spring integration for standard Kafka clients, the Kafka Streams DSL, and Processor API applications. Using these libraries allows you to focus on writing the streams processing logic and leave the configuration and dependent object construction to the Spring dependency injection (DI) framework. Here is the orders-service Kafka Streams component that aggregates orders and stores them by key in a state store:
@Autowired
public void orderTable(final StreamsBuilder builder) {
logger.info("Building orderTable");
builder
.table(
this.topic,
Consumed.with(Serdes.String(), orderValueSerde()),
Materialized.as(STATE_STORE))
.toStream()
.peek((k,v) -> logger.info("Table Peek: {}", v));
}
The @Autowired annotation above instructs the Spring DI framework to invoke this function on startup, providing a StreamsBuilder instance that we use to construct our Kafka Streams DSL application. This method allows us to write a class with a narrow focus on the business logic leaving the details of constructing and configuring the Kafka Streams supporting objects to the framework.
Configuration
Spring provides a robust configuration library allowing for a variety of methods for externalizing configuration for your service. At runtime, Spring can merge values from properties files, environment variables, and program arguments to configure the application as needed (order of precedence available in the documentation).
In the orders-service example, we have chosen to utilize properties files for Spring for Apache Kafka related configuration. Default configuration values are provided in the embedded application.properties resource, and we override them at runtime by using external files and the Profiles feature of Spring. Here, you can see a snippet of the default application.properties resource file:
# ###############################################
# For Kafka, the following values can be
# overridden by a 'traditional' Kafka
# properties file
bootstrap.servers=localhost:9092
...
# Spring Kafka
spring.kafka.properties.bootstrap.servers=${bootstrap.servers}
...
As an example, the value of spring.kafka.properties.bootstrap.servers is provided by the value in bootstrap.servers using the ${var.name} placeholder syntax.
At runtime, Spring looks for a config folder in the current working directory of the running process. Files discovered in this folder that match a pattern of application-<profile-name>.properties will be evaluated as an active configuration. Active profiles can be managed by setting the spring.profiles.active property in a file, on the command line, or in an environment variable. In the streaming-ops project, we deploy a set of properties files that match this pattern and set appropriate active profiles with the SPRING_PROFILES_ACTIVE environment variable.
Dependency management
In the orders-service application, we choose to use the Spring Gradle and the Spring dependency management plugin. The dependency-management plugin will subsequently manage the remaining direct and transitive dependency versions for us, as shown in the build.gradle file:
plugins {
id 'org.springframework.boot' version '2.3.4.RELEASE'
id 'io.spring.dependency-management' version '1.0.10.RELEASE'
id 'java'
}
The following Spring libraries can be declared without explicit version numbers as the plugin will provide compatible versions on our behalf:
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'org.springframework.boot:spring-boot-starter-webflux'
implementation 'org.apache.kafka:kafka-streams'
implementation 'org.springframework.kafka:spring-kafka'
...
REST services
Spring provides REST services with declarative Java annotations to define HTTP endpoints. In the orders-service, we leverage this to provide the API front end to queries of the Kafka Streams state store. We are also utilizing the asynchronous libraries provided by Spring for non-blocking HTTP request processing, for example:
@GetMapping(value = "/orders/{id}", produces = "application/json")
public DeferredResult<ResponseEntity> getOrder(
@PathVariable String id,
@RequestParam Optional timeout) {
final DeferredResult<ResponseEntity> httpResult =
new DeferredResult<>(timeout.orElse(5000L));
...
See the full code in the OrdersServiceController.java file.
Testing
The Confluent blog contains many helpful posts detailing Spring for Apache Kafka testing (see Advanced Testing Techniques for Spring for Apache Kafka, for example). Here, we will briefly show how easy it can be to set up a test using Java annotations that will bootstrap Spring DI as well as an embedded Kafka for testing Kafka clients, including Kafka Streams and AdminClient usage:
@RunWith(SpringRunner.class)
@SpringBootTest
@EmbeddedKafka
@DirtiesContext(classMode = DirtiesContext.ClassMode.AFTER_CLASS)
public class OrderProducerTests {
...
With these helpful annotations and the Spring DI framework, the scaffolding of a test class that uses Kafka can be as easy as:
@Autowired
private OrderProducer producer;
...
@Test
public void testSend() throws Exception {
...
List producedOrders = List.of(o1, o2);
producedOrders.forEach(producer::produceOrder);
...
See the full OrderProducerTests.java file for the complete example.
Validating in dev
The orders-service code contains a set of integration tests that we use to validate the behavior of the code; the repository contains CI jobs that are invoked on PRs or pushes to the main branch. Once we are confident that the application behaves as we would expect, we want to deploy it to a dev environment to build, test, and further confirm the behavior of the code.
The streaming-ops project runs its microservices workloads on Kubernetes and utilizes a GitOps approach to manage operational concerns. To deploy our new service to the dev environment, we are going to change the deployed version in dev by adding a Kustomize override to the orders-service Deployment and submit a PR for review.
When this PR is merged, the GitOps process kicks in, modifying the declared version of the orders-service container. After which, the Kubernetes controllers deploy the new version by creating replacement Pods and terminating previous versions.

Once the deployment is complete, we can validate the new orders-service by verifying that it is properly accepting REST calls and by checking its logs. In order to check the REST endpoint, we can open a prompt inside the Kubernetes cluster using a helper command in the provided Makefile, and then use curl to check the HTTP endpoint:
$ make prompt
bash-5.0# curl -XGET http://orders-service
curl: (7) Failed to connect to orders-service port 80: Connection refused
Our HTTP endpoint is unreachable, so let’s check the logs:
kubectl logs deployments/orders-service | grep ERROR
2020-11-22 20:56:30.243 ERROR 21 --- [-StreamThread-1] o.a.k.s.p.internals.StreamThread : stream-thread [order-table-4cca220a-53cb-4bd5-8c34-d00a5aa77e63-StreamThread-1] Encountered the following unexpected Kafka exception during processing, this usually indicate Streams internal errors:
org.apache.kafka.common.errors.GroupAuthorizationException: Not authorized to access group: order-table
These errors are likely orthogonal and thus will require independent fixes. Regardless of how we address them, we want to quickly return our system back to a functional state. GitOps provides a nice path for expediting this process by reverting the previous commit. We use the GitHub PR revert feature to stage a subsequent PR that reverts the changes.

Once this PR is merged, the GitOps process will apply the reverted changes, moving the system back to the previous functional state. It is wise to keep changes small and incremental to better support this capability. The dev environment is useful for rehearsing rollback procedures.
We’ve identified two issues with the new service that caused those errors. Both of them are related to default configuration values in the new service, which differs from the original.
- The default HTTP port was different, causing the Kubernetes Service to be unable to route traffic to the orders-service properly.
- The default Kafka Streams application ID was different from the configured Access Control List (ACL) configuration in Confluent Cloud, denying our new orders-service access to the Kafka cluster.
We decide to submit a new PR correcting the default values in the application. The changes are found in the configuration files located in the deployed Java Archive (JAR) resources.
In the application.yaml file, we modify the default HTTP service port:
Server: Port: 18894
And in the application.properties file (which contains the Spring for Apache Kafka relevant configurations), we modify the Kafka Streams application ID to the value configured by the Confluent Cloud ACL declarations:
spring.kafka.streams.application-id=OrdersService
Upon submitting the new PR, the GitHub Actions based CI/CD process will run tests. After the PR is merged, another Action will publish a new version of the order-service Docker image.
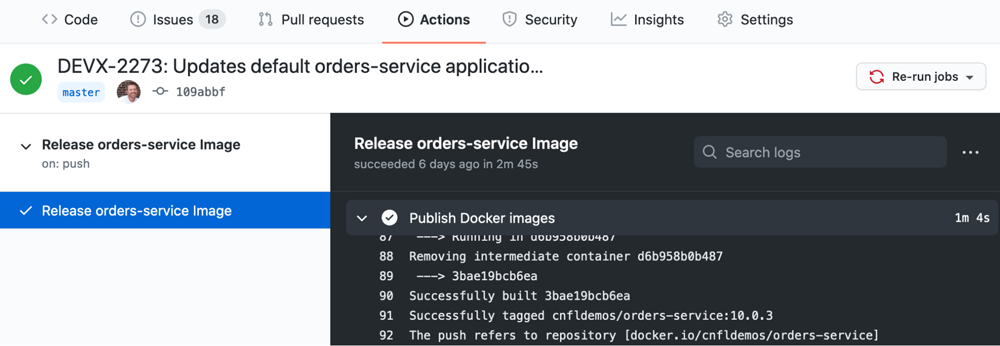
Another PR with the new orders-service version will allow us to deploy the new image with the proper defaults back to the dev environment and re-validate. This time after the deployment, we can interact with the new order-service as expected.
$ make prompt
bash-5.0# curl http://orders-service/actuator/health
{"status":"UP","groups":["liveness","readiness"]}
bash-5.0# curl -XGET http://orders-service/v1/orders/284298
{"id":"284298","customerId":0,"state":"FAILED","product":"JUMPERS","quantity":1,"price":1.0}
Finally, from our development machine, we can use the Confluent Cloud CLI to stream the orders from the orders topic in Avro format (see the Confluent Cloud CLI documentation for instructions on setting up and using the CLI).
➜ ccloud kafka topic consume orders --value-format avro
Starting Kafka Consumer. ^C or ^D to exit
{"quantity":1,"price":1,"id":"284320","customerId":5,"state":"CREATED","product":"UNDERPANTS"}
{"id":"284320","customerId":1,"state":"FAILED","product":"STOCKINGS","quantity":1,"price":1}
{"id":"284320","customerId":1,"state":"FAILED","product":"STOCKINGS","quantity":1,"price":1}
^CStopping Consumer.
Promoting to prd
With our newly refactored and validated orders-service in hand, we want to finish the job by promoting it to production. With our GitOps tooling in place, this is a simple process. Let’s see how.
First, let’s evaluate a helper command that we can run to verify the difference in the declared versions of the orders-service in each environment. From a developer machine in the project repository, we can use Kustomize to build and evaluate the final materialized Kubernetes manifests and then search them for the orders-service image information. Our streaming-ops project provides helpful Makefile commands to make this easy:
➜ make test-prd test-dev >/dev/null; diff .test/dev.yaml .test/prd.yaml | grep "orders-service" < image: cnfldemos/orders-service:sha-82165db > image: cnfldemos/orders-service:sha-93c0516
Here, we can see the Docker image tag versions are different across the dev and prd environments. We are going to file a final PR that brings the prd environment in line with the current dev version. In order to do this, we are going to modify the image tag declared in the base definition for the orders-service, and we are going to leave the dev override in place. In this case, leaving the dev override in place has no material effect on the orders-service version deployed but will make future deployments to dev easier. This PR will deploy the new version to prd:
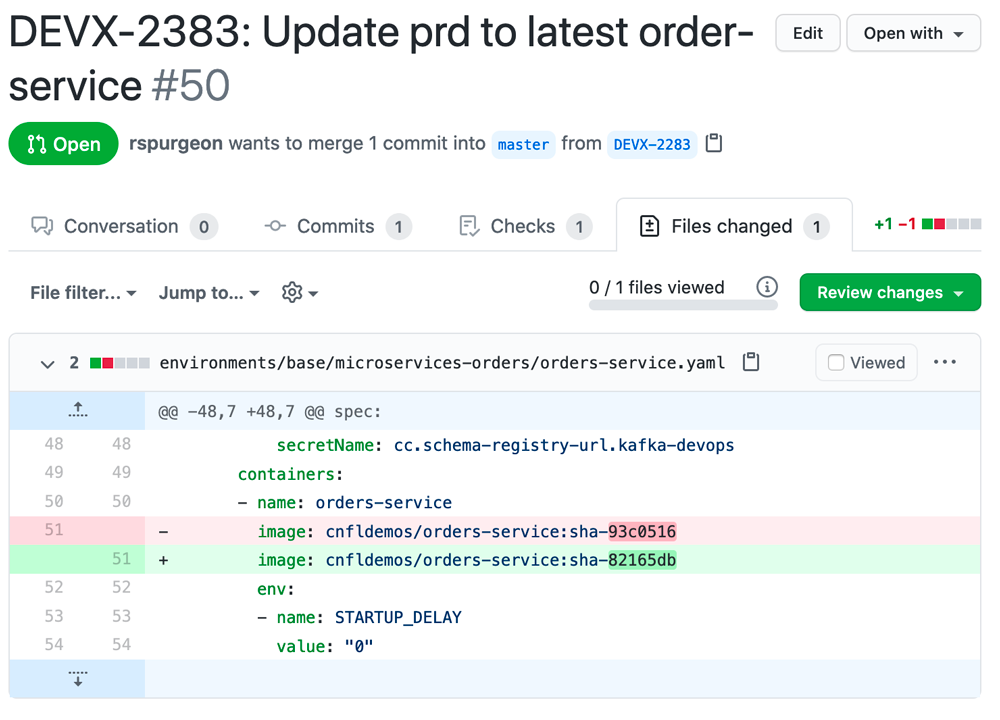
Prior to merging, we can rerun our test commands to verify that there will be no difference in the deployed versions of the orders-service, which is evident by a lack of output from the diff and grep commands:
➜ make test-prd test-dev >/dev/null; diff .test/dev.yaml .test/prd.yaml | grep "orders-service"
This PR is merged and the FluxCD controller in the prd environment deploys the proper version. Using jq and kubectl with the --context flag, we can easily compare the orders-service deployments across the dev and prd clusters:
➜ kubectl --context= get deployments/orders-service -o json | jq -r '.spec.template.spec.containers | .[].image'
cnfldemos/orders-service:sha-82165db
➜ kubectl --context= get deployments/orders-service -o json | jq -r '.spec.template.spec.containers | .[].image'
cnfldemos/orders-service:sha-82165db
We can use curl inside the cluster to verify that the deployment is working properly. First, set your kubectl context to your production cluster:
➜ kubectl config use-context <your-prd-k8s-context>
Switched to context "kafka-devops-prd".
The prompt helper command in the code repository helps us create a terminal in the prd cluster that we can use to interact with the orders-service REST service:
➜ make prompt Launching-util-pod-------------------------------- ➜ kubectl run --tty -i --rm util --image=cnfldemos/util:0.0.5 --restart=Never --serviceaccount=in-cluster-sa --namespace=default If you don't see a command prompt, try pressing enter. bash-5.0#
Inside the cluster, we can check the health of the orders-service:
bash-5.0# curl -XGET http://orders-service/actuator/health
{"status":"UP","groups":["liveness","readiness"]}
bash-5.0# exit
Finally, we can verify that orders are being processed properly by evaluating the logs from the orders-and-payments-simulator:
➜ kubectl logs deployments/orders-and-payments-simulator | tail -n 5
Getting order from: http://orders-service/v1/orders/376087 .... Posted order 376087 equals returned order: OrderBean{id='376087', customerId=2, state=CREATED, product=STOCKINGS, quantity=1, price=1.0}
Posting order to: http://orders-service/v1/orders/ .... Response: 201
Getting order from: http://orders-service/v1/orders/376088 .... Posted order 376088 equals returned order: OrderBean{id='376088', customerId=5, state=CREATED, product=STOCKINGS, quantity=1, price=1.0}
Posting order to: http://orders-service/v1/orders/ .... Response: 201
Getting order from: http://orders-service/v1/orders/376089 .... Posted order 376089 equals returned order: OrderBean{id='376089', customerId=1, state=CREATED, product=JUMPERS, quantity=1, price=1.0}
The orders-and-payments-simulator is interacting with the orders-service REST endpoint, posting new orders and then getting them back from the /v1/validated endpoint. Here we see 201 response codes in the log, which means that the simulator and the orders-service are interacting properly, and the orders-service is reading orders correctly from the Kafka Streams state store.
Summary
Successful microservice adoption requires careful coordination in your engineering organization. In this post, you saw how microservice frameworks are beneficial for standardizing development practices across your projects. With GitOps, you can help limit deployment complexities and empower critical capabilities like rollbacks. If you have ideas for areas related to DevOps that you’d like to see us cover, please feel free to file an issue in the project, or better yet, PRs are open!
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Kafka-docker-composer: A Simple Tool to Create a docker-compose.yml File for Failover Testing
The Kafka-Docker-composer is a simple tool to create a docker-compose.yml file for failover testing, to understand cluster settings like Kraft, and for the development of applications and connectors.


How to Process GitHub Data with Kafka Streams
Learn how to track events in a large codebase, GitHub in this example, using Apache Kafka and Kafka Streams.