[Webinar] Harnessing the Power of Data Streaming Platforms | Register Now
We’ll Say This Exactly Once: Confluent Platform 3.3 is Available Now
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Confluent Platform and Apache Kafka® have come a long way from the time of their origin story. Like superheroes finding out they have powers, the latest updates always seem to open up new possibilities. At Confluent, this has never been more apparent than in the release of Confluent Platform 3.3 and Apache Kafka 0.11 which we are thrilled to announce are available now.
What follows is a quick overview of the new tools and abilities you’ll find in Confluent Platform 3.3. Read along, or skip straight to the download. If you want a deep dive, be sure to check out our documentation reference notes.
What’s New in Confluent Platform 3.3
Exactly-Once Semantics
Available in: Apache Kafka, Confluent Platform, and Confluent Cloud
The one we have all been waiting for. In Apache Kafka 0.11 and Confluent Platform 3.3 you’ll find a few configs to turn on exactly-once messaging semantics. This builds off At Most Once and At Least Once guarantees to provide a more reliable, transactional streaming platform. Now, you no longer have to develop with lost or duplicated data in mind.
To achieve end-to-end exactly-once guarantees, Kafka introduced three concepts:
- An idempotent producer
- Transactions featuring atomic writes across partitions
- Exactly-once stream processing
Our CTO, Neha Narkhede, goes over this functionality in great detail in her recent blog, Exactly-once Semantics are Possible: Here’s How Kafka Does it. In short, what you need to know is these additions bring strong transactional guarantees to Kafka makes it easier than ever to write real-time, mission-critical streaming applications—the kind of system where data accuracy is of the utmost importance. From tracking ad views to processing financial transactions, you can do it all in real-time and reliably.
You may (wisely) be questioning the performance or other operational tradeoffs we’ve made to get this done. The good news is, the performance impact of adding EOS has been offset by a series of performance improving changes as you can see in these benchmarks. The undercover support—our own personal Alfred to exactly-once’s Batman—is that core Apache Kafka 0.11 got faster, as we touch on in the next section. These performance improvements compensate for the added cost of exactly-once processing, to a large extent. The end result is a manageable performance hit (from 5% up to 30% in the worst case), which we intend to reduce to virtually no performance cost in the next release.
Now these guarantees, as Neha puts it, are not magical pixie dust. You need cooperation from the application to achieve the end-to-end guarantees, unless you are using Kafka’s Streams API, in which case it is somewhat like magical pixie dust; all you need to do is set one config parameter (exactly.once=true) and you start getting exactly-once semantics for your Kafka Streams application.
To learn more about exactly-once support read Neha’s in depth blog post, or check out the Introducing Exactly-Once Semantics in Apache Kafka® online talk.
Who Doesn’t Want Faster?
Available in: Apache Kafka, Confluent Platform, and Confluent Cloud
In Apache Kafka 0.11 we went deep to give you even greater performance. This work was centered around the message structure. For those unfamiliar, records are sent to Kafka in batches which contain individual records. The messages and the batch records both hold all the metadata goodness that keeps Kafka happy.
What our engineers found was that by changing the message structure, reconfiguring the record batch to hold more and the records to hold less we could achieve noticeable savings in batch sizes and therefore improved throughput. These savings start with a batch size of 2 and continue with large batches of small messages.
These are approximately the gains you’ll see for a use case with small message sizes; like anything it will depend on your situation:
- Up to +20% producer throughput
- Up to +50% consumer throughput
- Up to -20% disk utilization
If you enable exactly-once, this will cause you to more or less break even. Our engineers put together a handy spreadsheet if you care to take a closer look.
Connector Isolation, Let’s Play Together Nicely.
Available in: Apache Kafka, Confluent Platform, and Confluent Cloud
The Kafka Connect API and its accompanying pre-built connectors have seen strong adoption in the past year. In fact, our annual user survey shows it doubling and that users are connecting more and more systems to Kafka using a wide range of connectors. The challenge with using connectors built by different developers is they might use different versions of the same libraries. Put the wrong versions of two connectors together, and things work poorly or not at all.
Apache Kafka 0.11 and Confluent Platform 3.3 now have a solution. You can still add connectors using the classpath just as before, but it’s far better to install connectors, transforms, and converters as plugins. When Kafka Connect needs to use a connector, transform, or converter class, the Kafka Connect worker finds the plugin where that named class exists and runs the connector using a classloader with all of the JARs in the plugin plus those provided by Kafka Connect, but isolated from all of the other JARs in all of the other plugins.
Installing plugins is also very easy. Each plugin is simply a directory with all of the JARs for that connector, transform, and/or converter, minus any JARs provided by the Kafka Connect runtime. Put one or more plugin directories into another directory that you put on the Kafka Connect workers’ plugin path. Details and examples are provided in our documentation.
Now you can truly mix and match connectors.
Confluent Control Center Stream Monitoring for Non-Java Clients
Available in: Confluent Platform
Most organizations have clients with multiple languages bringing data into Kafka. That’s how it should be, but you’ll still want to monitor the streams across all of those producers, regardless of what language they’re written in. In the past you could monitor Java producers and consumers in Confluent Control Center, but being limited only to Java isn’t ideal. We have a number of clients for a reason, so let’s monitor those too!
Today in Confluent Platform 3.3, Control Center will be able to provide stream monitoring for all clients. This lets you use the languages of your choice and track messages as they flow through your pipeline.
REST Proxy ACL Pass-Through (Security)
Available in: Confluent Open Source, Confluent Platform
If you’re a Kafka user, you likely are aware you can have an access control list stored in Zookeeper to manage user rights to topics, to authorize cluster management operations, and so on. Initially, our open source REST Proxy was only able to authenticate itself to the cluster as one user. This made it difficult to get full use of any ACLs you had configured. We decided to fix that!
With the REST Proxy available in Confluent Platform 3.3, individual users will be able to authenticate with the REST Proxy. The REST Proxy will look up this identity in your Zookeeper’s ACL to verify per-user authorizations.
Confluent CLI
Available in: Confluent Platform
A step in making Confluent Platform friendlier is our new Confluent command line interface (CLI). We always appreciate something that is easy and we know our developers do, too. So, what can you do with the Confluent CLI?
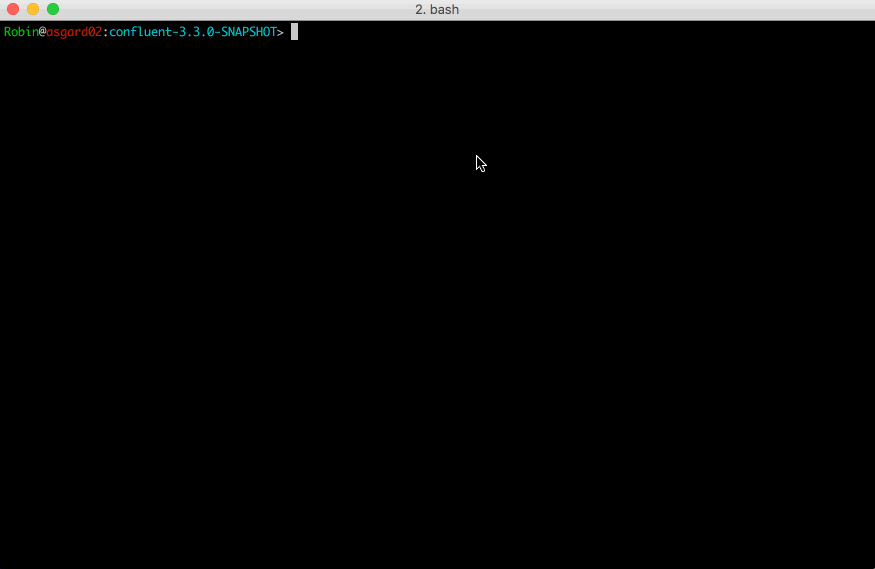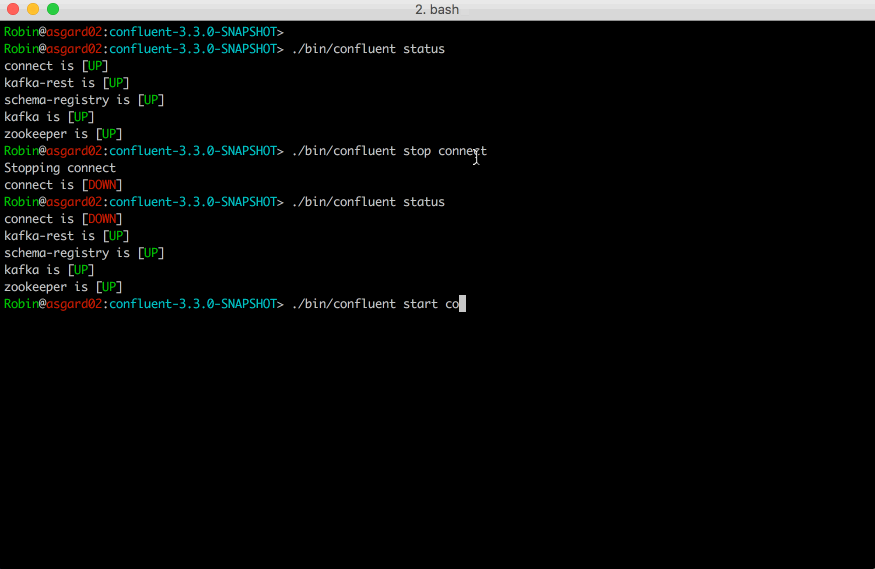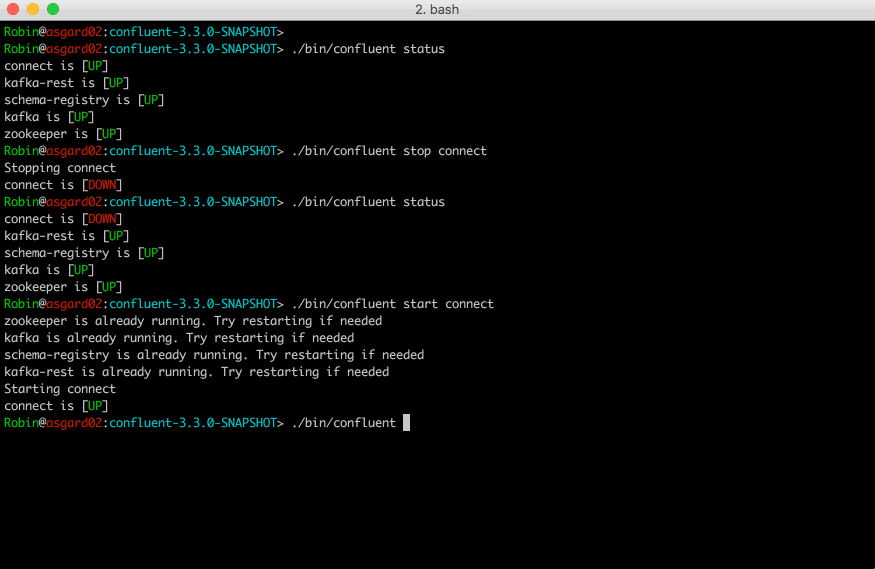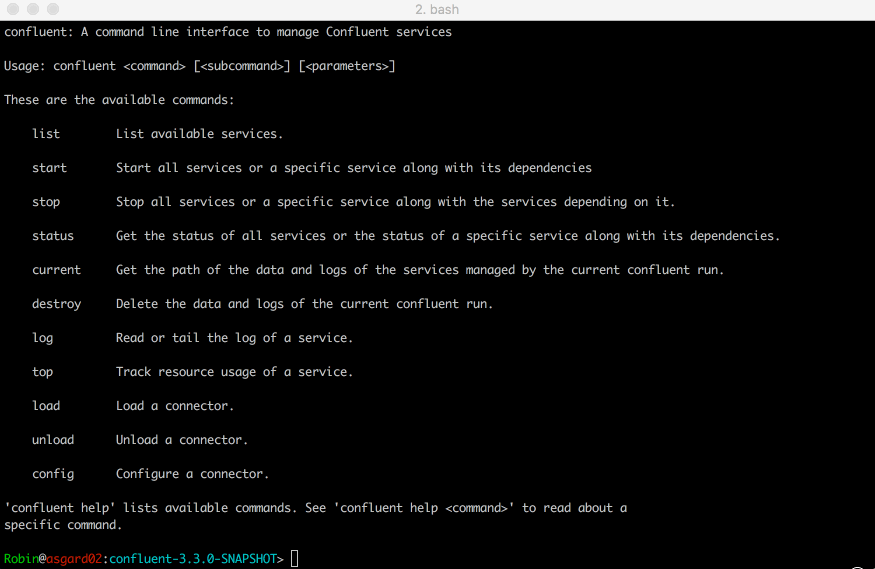
Quick demo of the Confluent CLI in action with Connect
Running a quick confluent in your terminal is all it takes to get started.
$ confluent
From there you’ll find a list of commands, able to start/stop services like Zookeeper and Kafka brokers, load and unload connectors, check health status, and more. We think it’ll make your lives a little easier. If you’d like to get started, the best place is with our new Confluent Platform Quickstart that makes use of the Confluent CLI.
Conclusion
At this point, I hope you’re excited to try out exactly-once delivery and play around with the CLI. Keep an eye out for more blog posts, webinars, and tutorials in the coming weeks.
So dig into the docs, find your download, and join the Confluent Slack community if you haven’t already. I’d love to know how your experience has been and your thoughts on the latest release – you’ll find me in Slack, @gehrig.
Just remember, with great power comes great responsibility. We can’t wait to see what you build.
For a complete overview of the latest in Confluent Platform 3.3, read our docs release.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...