Introducing Connector Private Networking: Join The Upcoming Webinar!
How to Get Your Organization to Appreciate Apache Kafka
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
If you want to enable your organization to leverage the full value of event-driven architectures, it is not enough to just integrate Apache Kafka® and wait for people to join the party.
Introduction
In June 2020, I presented in a Confluent online talk alongside the head of technology for Swiss Mobiliar, a leading insurance company in Switzerland. The talk was about the pains related to establishing Kafka in an organization and covered data governance. Because I received so much positive feedback, I decided to summarize our findings in this blog post and discuss our experiences at SPOUD, based on our observations, feedback from our customers and interviews of Kafkateers from around the world. I love to build things that change the way people perceive technology by making it more accessible. Kafka is a powerful beast, and this is why it needs more support in an enterprise in order to be understood and used by a broader audience. This article is about making Kafka more accessible in your enterprise, from the bottom up.
Why Kafka?
Kafka is crucial for any organization that benefits from real-time data. Kafka is fast, reliable, fault tolerant, durable, and reliable, modernizing architectures for new use cases large and small. From performant, scalable streaming data pipelines and message brokering, to event streaming, IoT data integration, and microservices communication, there are countless benefits across every industry.
Why Kafka is relevant to your organisation
Event-driven architectures play an increasingly important role in every enterprise data architecture because of its ability to enable real-time applications, as well as its ability to decouple systems, source data, and reuse data. These qualities address major pain points in current enterprise architectures.
So event-driven architecture to the rescue? At least on paper. In reality, you can only address these pains if there are enough people in your organization willing to adopt Kafka. For example, the value of decoupling in the overall architecture is only significant if existing and new interfaces use event-driven architectures. The same applies to data reuse; the probability of data reuse grows as the amount of data and the number of potential consumers increase.
Why your organisation is relevant to Kafka
This brings us to a very basic and unsurprising fact (one that technology enthusiasts don’t typically like): It’s not the technology that solves the problem but the collective decision to adopt the technology. In the same way, recycling does not significantly help the planet unless a majority of the population adopts it.
So the real challenge for Kafka is to win a majority inside an enterprise that can overcome architectural inertia. These people will be your Kafka fans, and they will be the reason that you can spend more time building your own Kafka fun park for and with them.
Understanding the reasons behind inertia
Kafka seems to have an easy game in winning the first few adopters in enterprises today (aka early adopters), withmany enterprises engaging in strong proof of concepts (PoCs) and, even before that, production-ready applications. But every so often, after embedding Kafka in the enterprise ecosystem and building the first few applications in production, the progress slows or pauses. What happened? Why are other teams not jumping on the shiny new bandwagon and joining the Kafka party? Answer: inertia—the natural tendency of people to stick with existing and known technologies rather than adopting new ones.
Thus, the challenge is a technology diffusion problem. That means, no matter how many millions of messages your Kafka cluster processes, no matter how well your cluster is secured, no matter how much you invested to make writing Kafka applications easy—it will not matter unless people understand why Kafka is important to them.
You can’t solve inertia problems with technology only, because inertia heavily relies on human capital.
So who are the people involved and how do you accelerate Kafka diffusion inside of your company? In 1962, sociologist Everett Rogers came up with a theory of the “diffusion of innovations,” which was later picked up in the domain of sales/marketing by Geoffrey Moore. You may recognize Moore from the book he authored called “Crossing the Chasm.” Rogers and Moore realized that the natural reaction of people toward new technology (or innovation) can be categorized into five different segments: innovators, early adopters, early majority, late majority, and laggards. These observations relate to overall market behaviour, but it’s likely that you have a very similar distribution inside of your organization.
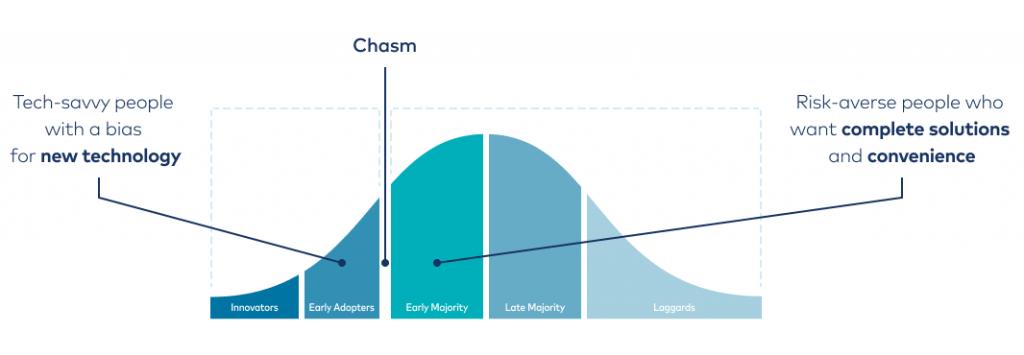 The technology adoption curve for Kafka inside an enterprise.
The technology adoption curve for Kafka inside an enterprise.
If you’re reading this blog post, chances are you’re an innovator or early adopter. You love new technology and think about how it can change lives for the better. That also means you belong to the smaller part of your organization, about 20%. Your job now is to show the other 80% of your organization how Kafka can change their lives for the better. What makes it even more difficult is that every segment needs slightly different reasons to adopt new technology. While early adopters appreciate understanding the intrinsic details of Kafka internals, from brokers, partitions, and replicas to transport guarantees, the majority of enterprise engineers appreciate having a quick entry into the value that Kafka offers: sending, receiving, and sourcing events (stream processing will be a focus for another time ). The difference of perceived value is commonly referred to as the chasm, and it’s an angle that many technology enthusiasts are not aware of.
Addressing the Kafka early majority
To cross the chasm, you need to be aware that the early majority perceives Kafka strictly from the concrete value that it generates for their work today. The closer you can address these people with the concrete value, the higher the chances are that they will buy into it. From their perspective, Kafka is an open source data subscription service that allows them to publish and consume event data. Think Twitter for data rather than brokers, topics, partitions, etc.
 Different perspectives between early adopters and early majority of Kafka illustrated.
Different perspectives between early adopters and early majority of Kafka illustrated.
The illustration above depicts the different levels of abstractions that early adopters like compared to the early majority. To go a step further, a business perspective has been added as well, which helps to remove some abstractions and focuses on data content, people, and their data use cases.
The ability to explain and use Kafka as a data subscription service is the key to onboarding your organization to Kafka. It allows you to elegantly explain the main architectural patterns of event-driven architectures, like decoupling, sourcing, and reuse, without going into technical details.
Winning fans among the early majority
This section is for the doers and builders among you: You like to get your hands dirty and do things. Sometimes, you might get the impression that in order to get things done you need to talk less. That is not the case here. If you want to spend more time doing things you like, start talking about your ideas and win fans. This effort relies on your ability to understand and relate to what other people think about your idea and to use this understanding to propel your own ideas. This is not about Kafka—this is about you being an innovator and a leader for ideas.
Essentially you want to do two things: Accelerate diffusion by offering motivation and reduce elements that cause friction. In other words, you want to start showing off Kafka as a subscription service among the early majority and you want to start building this subscription service as a means of convenience.
It is important to do both at the same time, allowing you to incrementally onboard new users through your Kafka journey. This way, you can incorporate their expectations and make them participants in the journey rather than just observers. Make sure that what you are communicating can be understood by the early majority. The following steps are helpful when talking to people:
- Share success stories
- Educate about event-driven architecture and Kafka
- Network and nudge
The strategy depends on whether you already have a few successful projects going or if you first need to prepare the stage for Kafka. Unfortunately, many engineers do not like these steps because they are not deemed “technical.”
While communication helps to slowly unfold Kafka’s value, you need to prepare the field for convenience. For most engineers, this is the best part because it actually involves engineering and product thinking:
- Data transparency or “seeing is believing”
- Self-service data and infrastructure access
- Low-level API abstractions
The following explains these six strategies in more detail.
Share success stories and educate
You probably have a joint architects meeting or internal engineering universities to accelerate internal knowledge sharing. Use these channels to share success stories from your Kafka PoCs and first projects. Repeat. Have at least one talk per quarter from the beginning. Avoid overwhelming colleagues with technical details. Remember that the early majority may lose interest in unnecessary complexity. Also, keep an eye out for interesting reference material to share from other companies in your industry related to Kafka. This step is essentially technical marketing inside your organization.
Network and nudge people
This is a tricky one. Many engineers don’t like the active networking component, so you need to talk to the influencers in your organization and gently nudge them towards Kafka Influencers are people you probably already know because they are valued for their opinions on technology. There are two kinds of influencers: the ones that push the organization to do new things and the ones that don’t. If you belong to the first group, make some friends there and also begin talking to the second group to collect and test arguments that you will likely encounter on your path to Kafka adoption.
At some point, when you have your first influencers interested, you need to start talking with others up the hierarchy ladder and test their awareness of event-driven architectures and how your organization can benefit from adopting them. This scenario resembles a 1:1 sales pitch, and while you might not like this step, consider it as a career-building opportunity.
Seeing is believing
Seeing Kafka is as important as talking about it. Sounds easy, but it’s not. As you know, Kafka comes without visualization. It resembles a black box in that aspect.If you want to see your data in Kafka, you have to probe it with command line tools and invest in tools like Confluent Control Center. While these tools are very valuable and help you to walk the first few Kafka miles in your projects with ease, they are not alone sufficient to win the early majority, because they emphasize the technical details needed to operate Kafka.
Using these tools will force you to explain the technical details of Kafka rather than talk about the value that Kafka creates. In the same way, you don’t want to explain to someone the essentials of driving a car by showing off your car’s engine.
What you need is something easier, more elegant, and more abstract. You want to show data streams rather than topics and partitions on the first level. This is essentially what SPOUD built as a product and now offers to the world— a streaming data catalog for Kafka.
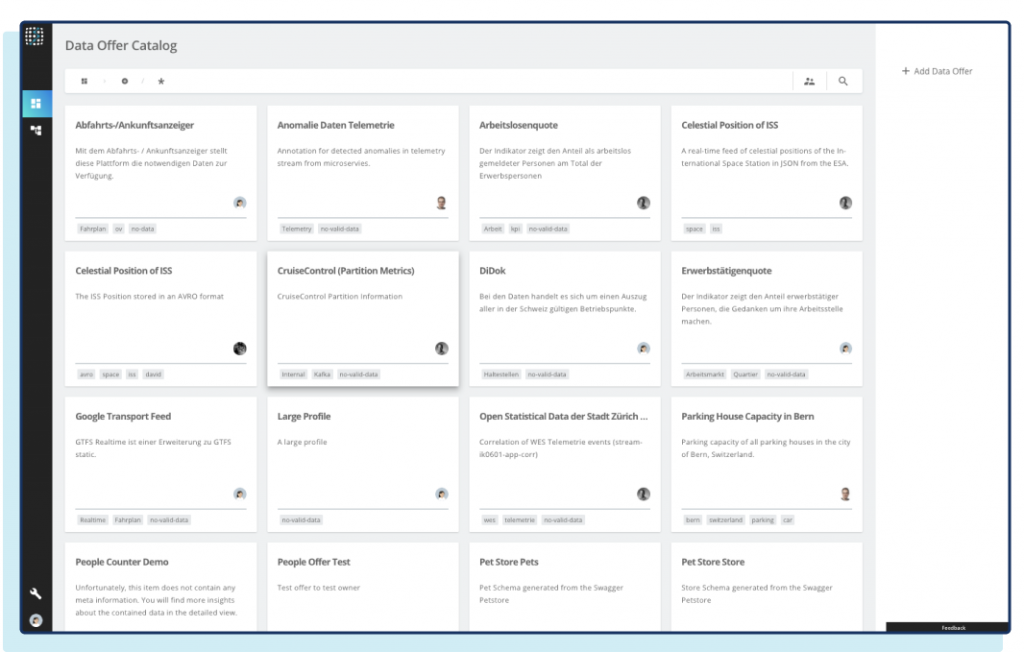 SPOUD Agoora: convenience through a data-centric view on Kafka
SPOUD Agoora: convenience through a data-centric view on Kafka
SPOUD Agoora is a SaaS product that easily connects to your cloud and on-premises Kafka through simple agents. Agoora targets organizations that want to add convenience to Kafka. Agoora abstracts Kafka topics as data offers with owners, permissions, documentations, schema, topology, and data quality. It provides everything you need to understand what a data stream means and whether it will solve your problems. SPOUD Agoora is currently in the open beta phase, aiming for freemium and enterprise subscription models.
Self-service access
Another challenge you need to address is to reduce the big learning curve of using Kafka and to enable users to quickly implement Kafka with minimum effort. AWS or Twitter convenience is the level you are aiming for in order to onboard the early majority onto the platform. Some organizations achieve this experience by adopting a fully managed offering like Confluent Cloud.
Also, the value of Kafka for other teams rises with the growing number of data streams offered. You might know this phenomenon as the network effect or as Metcalf’s law. To get more people to use Kafka, you need to simplify the data consumption and production. It’s a chicken and egg problem. You cannot get more people using Kafka if there is no data. The main problem is to convince data producers in enterprises to publish their data as real-time events in Kafka. Unfortunately, one reason why events do not exist is because data producers do not have Kafka knowledge, or the system they run does not provide Kafka connectivity out of the box.
Don’t reinvent the wheel
One word of warning in case you start to implement your own frameworks, processes, and tools on top of Kafka: Pay attention to where current efforts in the Kafka community are headed and how this relates to what you are building. It’s possible that something you decide to build today will be delivered by the community a few months later. The existing ecosystem around Kafka is big and rapidly growing, which is one of the most important benefits to Kafka, but can also be a risk. For example, building your own Kafka cluster on prem might be the most important first step for your organisation, or it could become obsolete in the next 12 months because you decide to switch to Confluent Cloud. As a rule of thumb, don’t build anything yourself along the major axis of change that Confluent and Kafka are already working on themselves.
When the fun park starts to get crowded…
As soon as you have more than two to three teams working with Kafka at the same time, you may start to experience some side effects of your success. Kafka is a shared resource, and as such, you often stand on each other’s feet. Side effects can be quite trivial at the beginning like having no consistent topic naming convention for all teams, but they soon will grow into overall stream dependency and schema stability challenges. Imagine a stream that you consume has a change in schema or produces data with lower data quality. Such changes can potentially have severe consequences.
This is why we believe that some of the first things you need to add to your convenience layer is a way to link topics to people (ownership), to protect some topics from being visible altogether, and to understand stream dependencies (topologies). As a whole, you want to enable a certain level of collaboration that counters the side effects of using shared Kafka resources.
One way to approach this is to build it all yourself, which is a lot of fun. If you can’t afford to do this, SPOUD is here to help. Our vision is to enable collaboration on Kafka to build a data as a product culture. We’d love to have you as beta testers alongside companies like Mobiliar.
To get started with SPOUD Agoora and Kafka, check out Agoora and the Streaming Audio podcast.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Tech-Enabled Metropolises: The Role of Data Streaming in Smart Cities
According to the World Bank, around 56% of the world’s population currently live in cities. By 2050, it’s predicted this will rise to 70% (with the global population more than doubling in the same time frame). This acceleration toward urbanization is putting city infrastructure under enormous strain



Unlocking Industry 4.0: Rise of Smart Factory with Data Streaming
In the era of Industry 4.0, the fusion of smart, autonomous systems with digitization is propelling manufacturing and supply chain operations into uncharted efficiency. Industry 4.0, otherwise known as the Fourth Industrial Revolution, marks the normalization of the smart factory.